通信界訊 文生圖在最近一年取得了顯著的進步,DreamBooth 定制化生成工作,進一步證明了文生圖的潛力,并且廣泛引起了社區(qū)關(guān)注,相比于單概念生成,在一張圖內(nèi)定制多個概念是更加有趣且具有廣泛應(yīng)用場景(AI 影樓,AI 漫畫生成....)。
相比于單概念定制生成取得的成功,阿里提出的 Cones 和 Adobe 提出的 Custom Diffusion 作為現(xiàn)有的多定制概念生成方法仍存在兩個挑戰(zhàn):
-
首先,他們需要為每一種多個概念的組合都學(xué)習(xí)單獨的模型,這可能會受到以下影響:1)無法利用已有的模型,比如一個新的需要定制的多概念組包含三種概念 {A,B,C},無法從已有的 {A,B} 的定制模型中獲得知識,只能重新訓(xùn)練。2)當(dāng)需要定制的概念數(shù)量增加時,計算資源的消耗指數(shù)上升。
基于此,阿里巴巴和螞蟻集團的研究團隊提出了組合式的多概念定制生成方法:Cones 2,能同時定制更多物體,且生成圖片質(zhì)量顯著提升。

論文主頁:Cone 2
https://arxiv.org/abs/2305.19327
項目主頁:Cones-page
https://cones-page.github.io
該團隊的前作 Cones 獲得了 ICML 2023 的 oral,并且在推特獲得了廣泛關(guān)注。

Cones 2 優(yōu)勢主要體現(xiàn)在 3 個方面。(1)使用簡單而有效的方法來表示概念,可以任意組合,復(fù)用各種訓(xùn)練好單概念,從而進行多定制概念生成,而無需為多概念進行任何重新訓(xùn)練。(2)使用空間布局作為指導(dǎo),這在實踐中非常容易獲得,用戶只需要提供一個 bounding box,即可以控制每個概念的特定位置,并同時減輕概念之間的屬性混淆。(3)在一些具有挑戰(zhàn)性的場景下也能取得令人滿意的性能:進行語義相似的多定制概念的生成,如定制兩只狗,并且可以交換眼鏡;在概念數(shù)量上,也可以合成六個概念。

方法
1. 基于擴散模型的文本引導(dǎo)圖像生成
擴散模型學(xué)習(xí)從正態(tài)分布噪聲中逐步去噪來恢復(fù)真實的視覺內(nèi)容,該過程實際上是在模擬可逆的長度為 T=1000 的馬爾可夫鏈。在文本到圖像任務(wù)中,條件擴散模型 的訓(xùn)練目標(biāo)可以簡化為重建損失:
文本嵌入 通過交叉注意力機制注入到模型 中。在推理時,網(wǎng)絡(luò)通過迭代去噪 進行采樣。
2. 殘差文本嵌入表示概念
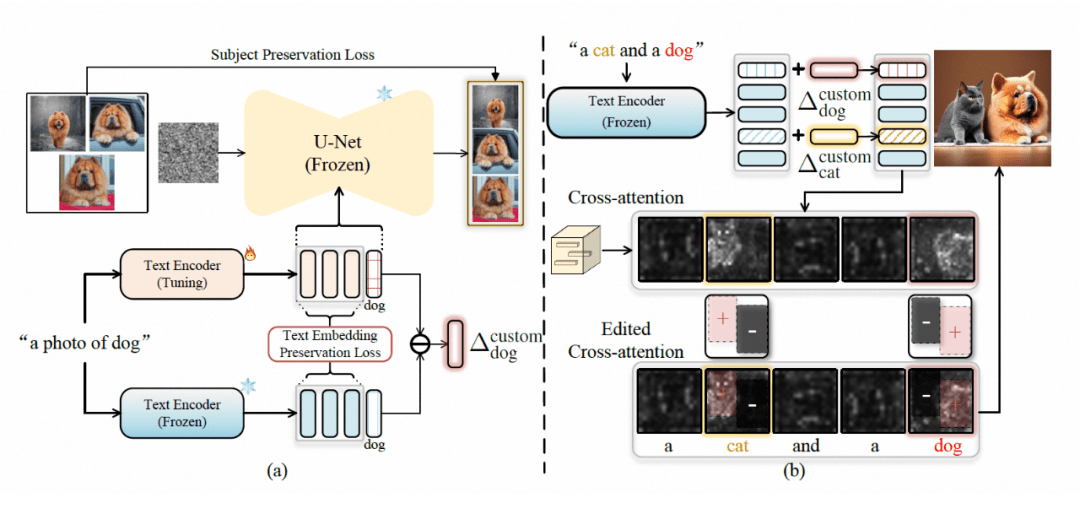
為了可以定制化生成用戶需要的特定概念,模型首先需要“記住”這些概念的特征。由于改變預(yù)訓(xùn)練模型參數(shù)往往會導(dǎo)致模型的泛化性下降,Cones 2 選擇針對每個特定概念學(xué)習(xí)一個合適的編輯方向。將這個方向作用于概念對應(yīng)的基類的特征編碼上,就可以得到定制化的結(jié)果,這個方向稱為 residual token embedding。
舉個例子,在使用 Stable Diffusion 生成圖像“一只狗坐在海灘上”時,整個生成過程由文本經(jīng)過文本編碼模型得到的文本編碼控制,那么只需要將“狗”對應(yīng)的文本編碼做合適的偏移,就可以讓模型生成出定制化的“狗”。為了得到 residual token embedding,首先需要用給定的數(shù)據(jù)微調(diào)文本編碼模型,在訓(xùn)練過程中 Cones 2 通過引入文本編碼保持損失,限制微調(diào)后的文本編碼器的輸出和原始預(yù)訓(xùn)練的文本編碼器的輸出盡可能接近。
同樣參考上面的例子,給定“一只狗坐在海灘上”作為輸入,這兩個文本編碼器輸出的文本編碼,只在定制化概念對應(yīng)的類別詞(狗)這里差別較大,在其他詞(海灘等。。。)的部分盡可能保持輸出一致。結(jié)合原本的生成模型,微調(diào)后的文本編碼器具有定制特定概念的能力,由于微調(diào)過程采用了文本編碼保持損失的約束,這種能力可以通過計算微調(diào)過的文本編碼器和原始文本編碼器在類別詞部分的平均差異,來得到需要的 residual token embedding:
基于上述方法得到殘差表示,是可以重復(fù)使用并且即插即用的。在做多概念定制化生成的時候,只需要將每個定制概念所對應(yīng)類別詞的文本編碼加上對應(yīng)的殘差項即可。
3. 通過空間布局引導(dǎo)多概念組合生成
交叉注意力層之間的注意力圖如下 ,交叉注意力圖直接影響最終生成的空間布局,多概念定制生成的圖片中的一個問題是某些概念可能無法顯示。為了避免這種情況,Cones 2 在希望其出現(xiàn)即用戶通過 bounding box 指定的區(qū)域中增強目標(biāo)概念的激活值。另一個問題是概念間的屬性存在混淆,即生成圖像中的概念可能包含其他概念的特征。
為了避免這種情況,則希望削弱每個對象出現(xiàn)在用戶指定區(qū)域外的激活值。結(jié)合上述兩種想法,Cones 2 提出了一種根據(jù)預(yù)定義布局 指導(dǎo)生成過程的方法。在實踐中,將布局 定義為一組概念邊界框,由每個概念的的指導(dǎo)布局 組成。在希望概念 出現(xiàn)的區(qū)域中將 的值設(shè)置為正值,并在與該概念無關(guān)區(qū)域中將 的值設(shè)置為負(fù)。對注意力圖進行編輯。
實驗
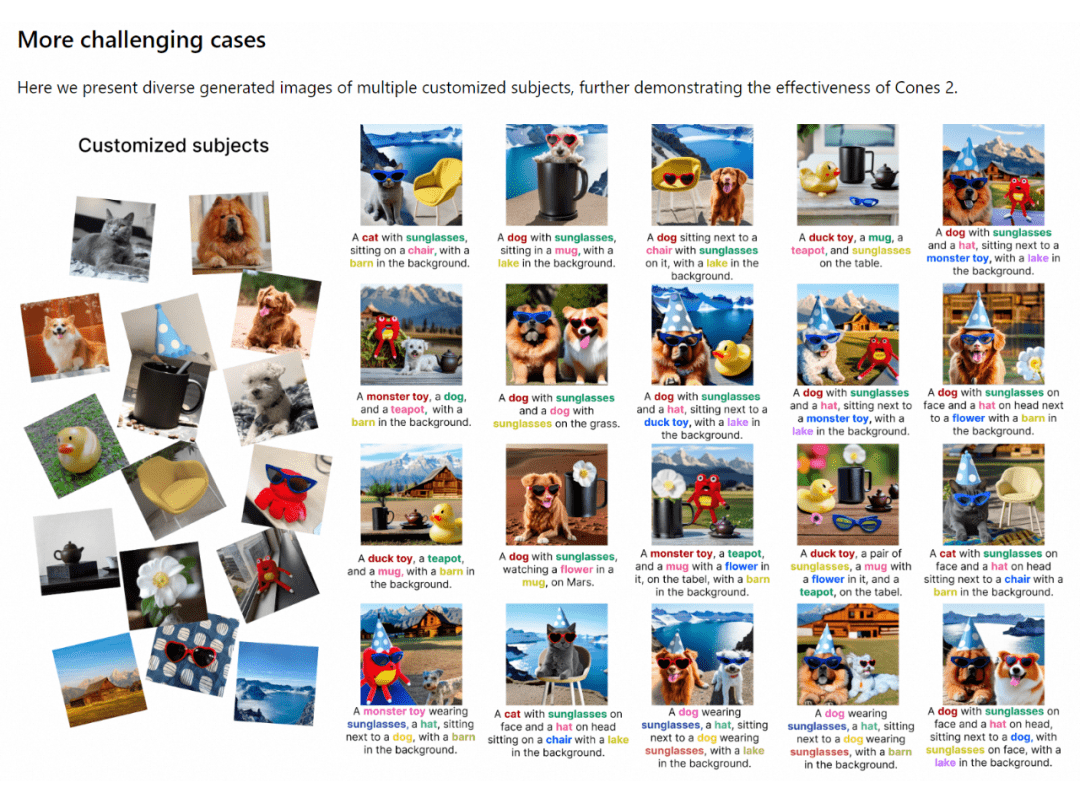
將生成結(jié)果與現(xiàn)有方法進行對比,從訓(xùn)練的計算復(fù)雜度,以及生成效果,均有顯著提升。



并且在處理更多概念的生成,以及處理語義相似物體的場景下,都有著優(yōu)越表現(xiàn)。

應(yīng)用前景
多定制概念生成除了能夠生成更加高質(zhì)量,內(nèi)容豐富的圖片外,同時具有廣泛的應(yīng)用前景,現(xiàn)在大火的 ControlNet 更多是控制生成圖片中的結(jié)構(gòu),多概念定制生成可以對生成的內(nèi)容進行控制,使文本到圖像的生成更加可控,進一步提高了文生圖模型的應(yīng)用價值。比如,創(chuàng)作者通過輸入文本,通過幾個定制好的角色概念,進行多格漫畫生成;通過組合用戶定制的自身角色概念和商家提供的多個試戴試穿的定制概念(衣服,首飾,鞋帽等等),實現(xiàn)多款服裝的試穿體驗。