周子垚,劉慶玲,陶劍英,林云
(哈爾濱工程大學信息與通信工程學院,黑龍江 哈爾濱 150001)
0 引言
全球的移動通信技術已經步入了5G 時代,商用化的5G 技術可以支持低時延高可靠的物聯網業務,使云端智能下落到用戶終端的愿景成為現實。但是隨著人工智能、通信技術、硬件設備等領域飛速發展,用戶也提出更高層次的服務需求[1]。在此基礎上,6G 將會演進5G 典型場景,推出超級無限帶寬、超大規模連接、極其可靠通信,并擴展普惠智能、通信感知融合等新型服務場景[2]。這些服務場景將會產生海量數據,采用傳統的云計算框架將邊緣數據進行集中處理的模式不僅效率低、能耗大,而且還會因為時延等問題降低服務質量,邊緣計算(EC,Edge Computing)在這種背景下應運而生。
EC 是一種可以在網絡邊緣進行分析并處理數據的技術,通過部署邊緣計算平臺,讓本地終端直接接入就近的服務器進行實時處理,可以最大限度地減少上傳云端的數據量,釋放帶寬并降低服務成本。與此同時,在物理距離縮短的情況下,數據傳輸的時延也會大大降低,為用戶提供更好的服務質量。
增強邊緣計算還有另一個發展方向——人工智能(AI)。近幾年AI 技術不斷取得突破性進展,但是隨著性能的提升,模型的體量以及能耗也在不斷增加。現階段的邊緣終端(多數為傳感器)通常會在mW 級別的功耗下運作,此外大部分時間將會以μW 級別的功耗進入休眠狀態。在資源有限的條件下保證模型的性能,是一個具有挑戰性的工作,包括知識蒸餾以及結構剪枝在內的模型輕量化技術掀起一股新的研究熱潮。在這種背景下,實現邊緣計算和模型輕量化的有機結合,普及邊緣設備的智能服務將成為商業化發展的一種主流趨勢。本文重點針對邊緣計算和模型輕量化的基本理論、關鍵技術、發展現狀等進行探討和分析。
1 邊緣節點網絡部署
鑒于6G 系統的復雜性、先進性以及對產業的引領和帶動作用,各主要發達國家紛紛加大投入,深入展開研究,謀求競爭優勢。在5G 時代,深度學習的數據處理通常只能在云計算中心進行,該體系在處理邊緣數據時存在四點不足:(1)時延較大,難以滿足業務實時性需求;(2)數據流量過多,易導致信道堵塞;(3)能耗較大,會提高運營成本;(4)安全性較低,隱私數據存在相當大的泄漏風險。在5G 物聯網的基礎上,以網絡為基礎、云端處理器為中心,進行“云網融合”(架構如圖1 所示),做到網隨云動:云端處理器對網絡進行資源分配和實時調度;實現網絡云化:讓傳統的封閉式網絡打開大門,實現本地云化、智能化,實現資源彈性分配、快速組網、智能控制等目標[3]。這種以云端服務器為中心,設立邊緣節點,對邊緣服務器進行技術升級、優化管理方式,建設眾星捧月的網絡格局可以有效地解決現存問題,是一種潛力巨大的發展方向。本節將介紹邊緣計算的相關理論,并通過數據分析6G 網絡采用邊緣計算的優勢。
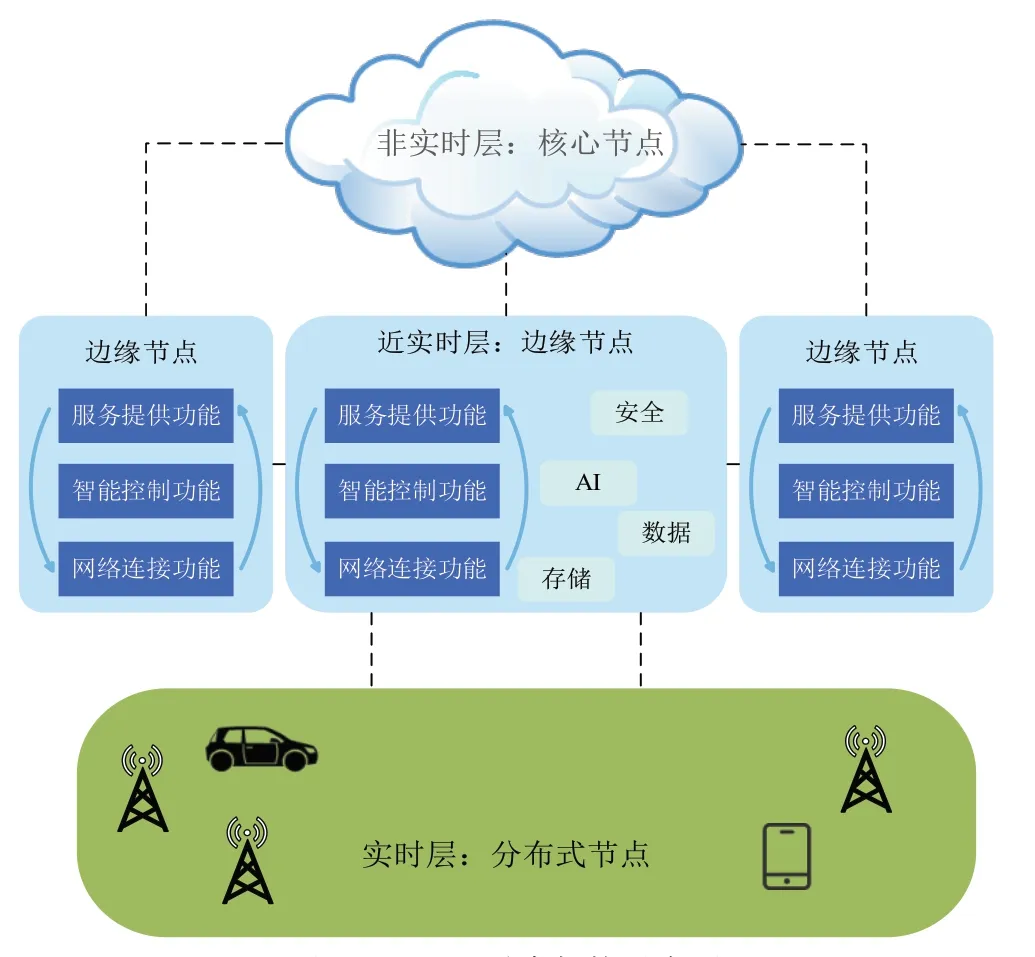
圖1 6G云網融合架構示意圖
1.1 邊緣計算(EC,Edge Computing)
邊緣計算是一種新型計算范例,由谷歌公司于2006年提出,用在網絡的邊緣執行計算任務。相比云計算,邊緣計算更貼近數據的源頭,可以在一定程度上減少數據傳輸過程中產生的延遲;同時,因為就近處理,無需將全部數據上傳到云端服務器,可以更好地保護隱私數據以防泄露,最大程度上避免信息被人惡意利用;此外,還可以大幅度減少通信能耗、最大程度上減輕網絡帶寬的壓力。
邊緣計算主要通過在終端設備和云服務器之間引入邊緣節點,在節點處對用戶任務類別進行判定,將時效要求較低、數據量大且需要進行深入分析的任務交付給云端中心服務器進行處理;讓規模小、要求實時智能分析的任務駐留在邊緣節點進行處理。因此,在智能業務中,數據量較大、需要大規模集中處理的任務可以繼續沿用云集中處理模式,邊緣計算則更適合小規模數據分析任務和本地服務[4]。邊緣計算的架構如圖2 所示:
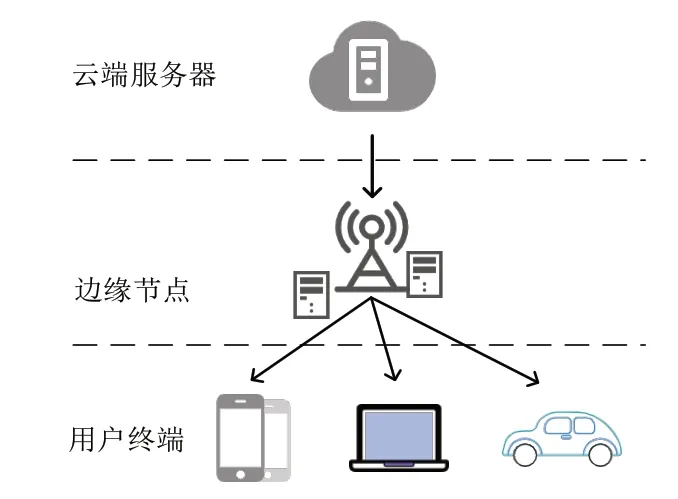
圖2 邊緣計算架構
近年來,各種傳感設備不斷升級,數據采集能力得到顯著提高,可以檢測到大部分工業生產過程中的實時信息。對于檢測過程中產生的海量數據,傳統的處理模式存在時延大、成本高等問題,無法滿足工業需求。鑒于邊緣計算的優點,可以被廣泛應用于工業生產環節中[5]。典型的應用場景有:基于深度學習的軸承故障診斷[6]和電力設備檢修[7],該應用場景通過邊緣計算進行故障診斷和缺陷檢測;對無人機進行綜合管理,實現大范圍數據采集和實時監控[8],從而加強園區的安防管理;在進行產品測評時,運用了EC 的虛擬現實和增強現實(VR/AR)技術也使工人分析數據更為高效。
雖然邊緣計算已經運用到眾多場景之中,但仍存在許多問題需要進一步改善,這些問題包括EC 性能過低、安全性不足、設備協作協議完善較差等。因此,為了早日實現6G 網絡的愿景、廣泛普及智能業務,這些問題都需要得到持續的關注并進行深入研究。
1.2 移動邊緣計算(MEC,Mobile Edge Computing)
歐洲電信標準協會于2016 年正式提出移動邊緣計算的概念,MEC 將一定的計算能力附加在基站上,而邊緣計算除基站外還在私有云、Cloudlet 等位置附有計算能力,這是二者最大的區別,MEC 和EC 的網絡部署圖如圖3 所示:
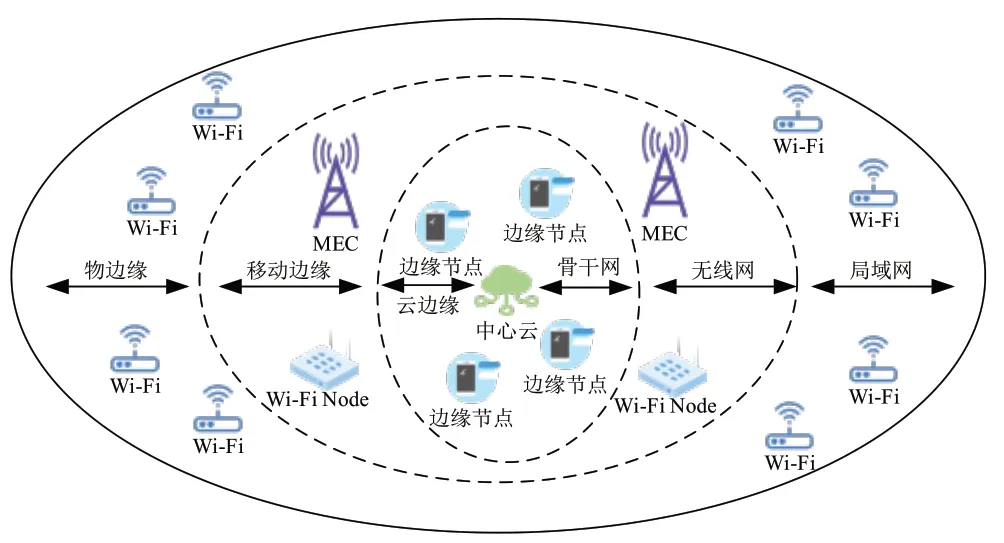
圖3 網絡部署圖
MEC 通過構建無線電接入網(RAN,Radio Access Network)層次的服務環境,使部分業務脫離核心網,進而節約資源、降低時延、提高服務質量。根據ETSI 所發布的白皮書,MEC 具有如下特征[9]:
(1)本地服務:MEC 可以脫離互聯網的其余部分實現自主運營,并能夠訪問本地網絡資源,這種特性對于M2M(Machine-to-Machine)場景十分重要。此外,由于MEC 和其他網絡存在隔離特性,可以有效提升數據安全性。
(2)鄰近性:MEC 布置在移動終端的最近位置,對于一些特定的計算密集型設備(例如增強現實、視頻分析)具有巨大優勢。
(3)低時延:MEC 就近部署在用戶設備附近,可以最大程度上避免本地數據和云端數據的交互過程,大幅度降低用戶服務時延,且覆蓋范圍內的用戶數量在一定程度上保持穩定,能夠減小服務器的帶寬壓力。
(4)位置感知:邊緣分布式設備通過低級信令進行信息實時共享,MEC 可以接收本地網絡設備的數據,實現設備定位。
(5)網絡上下文信息:提供網絡信息和實時上網數據服務的應用程序,可通過MEC 利用RAN 實時信息,對網絡狀態進行分析,協助運營商做出合理判斷,為用戶帶來更優質的服務。
MEC 的“鄰近性、低時延、位置感知”等技術特性,可以滿足6G 服務場景中的諸多需求(如表1 所示),為其帶來了廣泛的應用前景。

表1 服務場景需求
由表1 可知,MEC 可以適用于車聯網(IoV,Internet of Vehicles)、虛擬現實 增強現實(VRAR)、智慧醫療、公共安全、智慧城市等服務場景。車聯網結合MEC可以在車輛行駛過程中,通過分析環境信息、同網絡內其他車輛交互信息,為駕駛員提供合理建議,排除隱患并規避交通擁堵的風險;智慧醫療需要實時處理大量數據,應用MEC 可以為遠程醫療提供更有力的技術支持;智能家居系統可以利用大量物聯網設備進行實時數據監測,結合MEC 對家居設備的使用狀態進行調度,進而提高當代人們的家居安全性、便利性以及舒適性[10]。
MEC 在邊緣計算的基礎上進一步細化,將MEC 與人工智能、傳感探測等技術相融合,不斷深入研究、適應新場景、提升用戶體驗,進而擴展6G 業務的適用范圍,為智能入戶提供一個更光明的前景。
2 基于用戶終端的網絡模型輕量化
上文探討了6G 智能網絡的邊緣部署,但邊緣節點只是用戶終端和云服務器的中間環節,對于一些小數據量的分析任務,仍需終端設備自行處理。對于傳統的神經網絡模型,過去的學者們更注重于提升模型的識別精度和復雜環境下的適應能力,使得模型參數量和復雜度不斷提高,致使能耗成本激增。近幾年,得益于AI 技術的飛速發展,各行業的視線逐漸轉向人工智能在實際生活中的應用。由于移動端、嵌入式設備等平臺存儲資源少、處理器性能低、能耗受限,當前大部分高精度模型無法部署在用戶終端且難以實時運行。這要求傳統的深度神經網絡模型在保證性能的同時減少參數量和復雜度,模型輕量化也因此成為一個研究熱點[11]。
2.1 知識蒸餾(KD,Knowlegde Distillation)
知識蒸餾是一種新興的模型壓縮方法,其主要思想是讓規模小、結構簡單的學生模型通過學習在保證性能的前提下,獲取結構復雜的教師模型的知識。該方法可以看作是遷移學習的一種,其關鍵問題是如何將教師模型的知識遷移到學生模型,并在遷移過程中保證模型的性能不會降低甚至有所提升,這需要學者們加深對遷移過程的研究。
知識蒸餾的框架主要包含三部分,其結構如圖4 所示。該框架中,首先從教師模型輸出的結果中蒸餾出“知識”,再經過進一步的轉換交付給輕量級的學生模型,在該過程中要保證性能波動較小。在該過程中最重要的部分是“知識”的獲取。一方面,這個“知識”可以解釋為教師模型的輸出數據所包含的某些相近特性,且這些特性可以用于其它模型的訓練,部分文獻稱其為“暗知識”[12];另一方面,可將其理解為教師模型生成的一切可被其它模型利用的特征、參數等數據,“蒸餾”的過程就是發現并放大這些數據的相似性,并用于其它模型的訓練[13]。
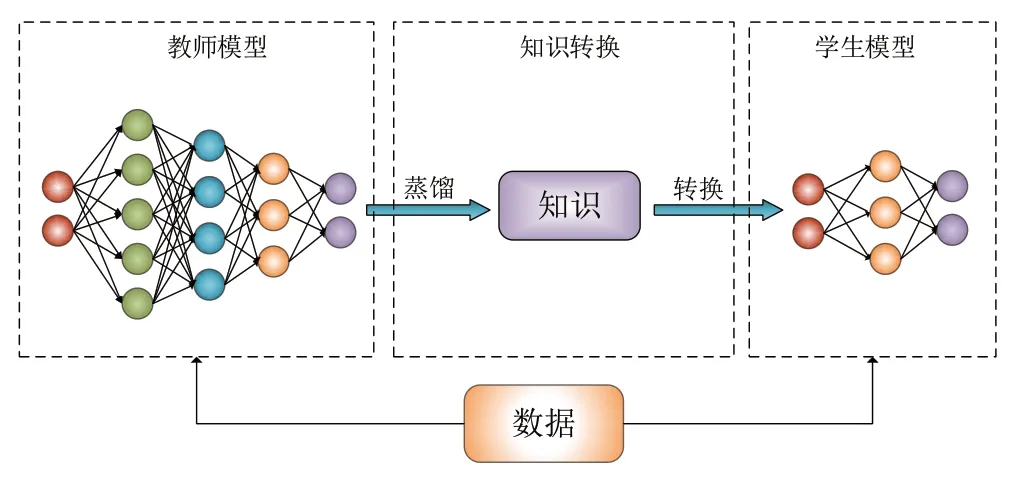
圖4 知識蒸餾框架
近幾年,研究人員已進行大量實驗,從表2 的數據中,可以看出蒸餾后的模型體量大幅度降低,并在保證精確性的同時提高模型效率。

表2 知識蒸餾性能表現
此外,很多主流技術的瓶頸問題,都可以通過知識蒸餾技術來解決,這些主流技術可參考如下示例:
(1)生成對抗網絡(GANs,Generative Adversarial Networks)往往計算復雜、存儲資源需求高,難以直接部署在移動設備上,結合知識蒸餾技術可以對生成器[14]、判別器[15]或同時對生成器判別器[16]進行簡化。目前在壓縮上,雖然GANs 結合知識蒸餾已獲取很多優異成績,但仍存有一些問題(如不易訓練、不可解釋等)需要研究人員進行更深入的研究。
(2)強化學習(RL,Reinforcement Learning),在很多領域中都存在深度強化學習模型的應用[17],如機器人控制[18]、完全信息博弈[19]和非完全信息博弈[20]等。但是該模型需要與外界進行大量交互來更新網絡參數,造成巨大的訓練開銷,結合知識蒸餾輔助訓練過程可以提升訓練效果并實現模型的輕量化。
(3)聯邦學習(FL,Federated Learning)可以在訓練的過程中最大程度保護數據隱私,這種方法將傳統機構的數據邊界打破,在現實中具有非常廣泛的應用前景。聯邦學習還支持本地數據訓練,并將訓練后的數據加密傳輸到服務器,但過大的數據量往往會占用大量帶寬,產生高昂的通信成本。將知識蒸餾部署在聯邦學習的各個環節,可以減少分布式聯邦學習所占帶寬。
從上述各個例子中可以看出,知識蒸餾可以在保證模型性能的前提下降低體量,實現復雜模型的小型化,進而部署到資源有限的邊緣設備上[21],使智能入戶成為現實。
2.2 神經網絡剪枝
近年來,神經網絡剪枝作為一種有效的模型壓縮方法為人們熟知。雖然多數的大型神經網絡學習能力出眾,但通過分析實驗過程中的數據可以發現,模型中存在部分結構無法發揮應有作用,因此神經網絡剪枝的想法油然而生:在不影響網絡性能的情況下去除多余的模型結構,從而降低模型體量[22]。具體做法如下:對網絡中的節點進行分析與評估,去除評估結果不理想的節點,進而實現模型輕量化(剪枝效果參考表3 數據),將中大型深度神經網絡部署在邊緣節點以及邊緣設備上。
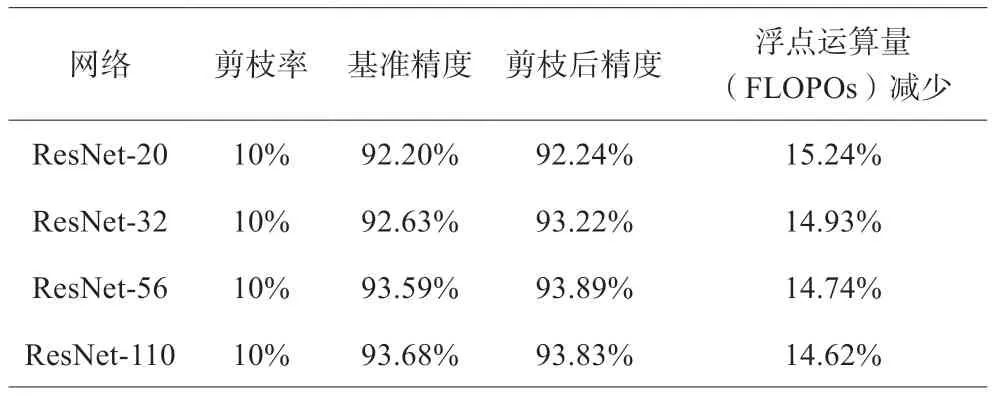
表3 SPF方法網絡剪枝性能表現
神經網絡剪枝主要分為兩種方式,分別為結構化剪枝和非結構化剪枝,其中非結構化剪枝主要通過刪減權重參數達成目的,而結構化剪枝則包含其它技術,如卷積核剪枝、通道剪枝等。
非結構化剪枝往往需要額外信息,在保持模型性能的同時提高稀疏性。剔除的參數可通過如下方法確定:最優腦損傷方法(OBD,Optimal Brain Damage)使用二階導數建立誤差函數的局部模型,選擇性地刪除網絡權重[23];最優腦外科醫生方法(OBS,Optimal Brain Surgeon)使用誤差函數的所有二階導數信息來執行修剪[24];以最小貢獻方差為修剪指標,通過偏置參數,比較偏置前后輸出數據的差異度來去除貢獻方差最小的連接參數[25]。
非結構化剪枝僅剔除部分參數,在降低計算量、參數量等方面表現較為平庸。結構化剪枝則對卷積核、通道進行優化,可以在整體結構上對神經網絡的性能進行提升。通過刪除一些對網絡整體貢獻度小的卷積核可有效地加速網絡推理時間,如通過比對每一層卷積核對輸出結果的貢獻度,選出冗余的卷積核進行修剪[26];從降低計算量角度進行考量,將網絡輸出精度較小的過濾器刪除,最大程度減少矩陣乘法運算,如基于過濾器剪枝的壓縮技術[27];通過對具有層相關閾值的通道進行修剪,將重要的通道和可忽略通道進行最優分離,如最優閾值法(OT,Optimal Thresholding)[28]。
上述的各種方法都可以在保持性能的前提下盡可能地縮小模型體量,降低運算量,為移動便攜式設備搭載更多的人工智能應用提供可能。
3 邊緣節點和模型輕量化在6G生態中的結合
隨著AI 技術的不斷發展,人們對智能生活的要求也會逐漸提高,AI 的設計路線也會向追求智能、靈活、安全、易部署的道路前進,在投入使用的過程中,智能設備需要面對四個角色:(1)設備制造商;(2)云廠商;(3)通信廠商;(4)算法供應商,構建完整的6G 智能生態需要四方協作發展、共同進步。但從歷史的經驗中可以發現,最重要的角色是設備制造商,其它三方始終存在一個痛點——眾多算法難以落實到硬件設備。
結合上文邊緣計算和模型輕量化的相關內容:在算法供應方進行輕量化處理,將高性能應用部署在邊緣設備,通過通信廠商設立的邊緣節點協調各方,勾連云端,進行任務分配,最大程度上提高網絡效率。通過這種方式,各方取長補短、互相協調,可以在一定程度上解決短板效應,推動6G 智能生態的發展與智能業務的全面落實。
4 結束語
本文聚焦6G“云網融合”前景,對6G 的智能業務發展方向進行分析,著重討論了邊緣計算、移動邊緣計算、知識蒸餾、結構剪枝的基本原理、關鍵技術和應用前景,通過數據分析,針對6G 智能生態的痛點進行論述,探討解決方案。但是隨著對6G 網絡深入研究以及協議細化,必定會有許多問題衍生出來。如何應對新生問題,并提升6G 的業務范圍、服務能力,推動未來社會的智能化仍需學術界的各方同仁共同努力。