0 ę²čį
¤oŠĆé„ĖąŲ„ŠWĮjŠC║Ž┴╦¤oŠĆ═©ą┼╝╝ągĪóé„ĖąŲ„╝╝ągĪóŪČ╚ļ╩ĮŽĄĮyĪóĘų▓╝╩Įėŗ╦ŃĄ╚ČÓĘNŪ░čž╝╝ągŻ¼ŠWĮjā╚Ė„╣سc─▄ē“═©▀^¤oŠĆ═©ą┼ĘĮ╩Į(╚ńZigBee)ą╬│╔ūįĮM┐ŚŠWĮjŻ¼ģf═¼Ėąų¬┼c╠Ä└Ē┤²£yģ^ė“ā╚Ą─ŽÓĻPą┼Žó▓ó░l╦═Įoė^£yš▀ĪŻį┌¤oŠĆé„ĖąŲ„ŠWĮjŠ▀éõųTČÓā×ä▌Ą─═¼ĢrŻ¼Ųõ╣سcį┌ļŖ│ž─▄┴┐ĪóöĄō■╠Ä└Ē─▄┴”Īó┤µā”─▄┴”Ą╚ĘĮ├µ┘Yį┤╩«ĘųėąŽ▐Ż¼ę“┤╦į┌öĄō■▓╔╝»┼c╠Ä└Ē▀^│╠ųąĄ─┬Ęė╔┼cöĄō■╚┌║Ž╩Ūę╗éĆė░Ēæš¹éĆŠWĮj╔·┤µĢrķg┼cöĄō■▓╔╝»ą¦┬╩Ą─ĻPµIąįå¢Ņ}Ż¼▀@ę▓╩Ū«öŪ░Ą─蹊┐¤ß³cų«ę╗ĪŻ¤oŠĆé„ĖąŲ„ŠWĮjšQ╔·ęįüĒŻ¼čąŠ┐š▀ę└ō■╩╣ė├ŁhŠ│įOėŗ┴╦║▄ČÓĮøĄõĄ─┬Ęė╔ģfūhŻ¼Ųõųą░³└©╗∙ė┌╣سcĘų┤žÖCųŲĄ─LEACH(Low-Energy Adaptive Clustering Hierarchy)ĪóČ©Ž“öU╔ó┬Ęė╔DD(Directed Diffusion)Īó╗∙ė┌Ąž└Ē╬╗ų├ą┼ŽóĄ─GEAR(Geographical and Energy Aware Routing)Ą╚Ą╚ĪŻ▒Š╬─ų„ę¬ėæšō╗∙ė┌Ęų┤ž┬Ęė╔Ą─öĄō■╚┌║Žå¢Ņ}Ż¼Ž┬├µīóęįLEACH×ķ╗∙ĄA╝ėęįĘų╬÷ĪŻ
1 LEACHģfūhĘų╬÷
LEACHģfūh╩Ūė╔MITĄ─HeinzelmanĄ╚īWš▀╠ß│÷Ą─ę╗ĘNė├ė┌¤oŠĆé„ĖąŲ„ŠWĮjĄ─Ą═╣”║─ūį▀mæ¬ĘųīėŠ█┤ž┬Ęė╔╦ŃĘ©Ż¼Ųõ╗∙▒Š╦╝ŽļŠ═╩Ūęį“▌å”×ķų▄Ų┌裣hĄžļSÖC▀xō±┤žŅ^╣سcŻ¼īóš¹éĆŠWĮjĄ──▄┴┐Ž¹║─▒M┴┐Ęų╔óį┌├┐éĆ╣سcųąŻ¼čėķLŠWĮj╔·┤µĢrķgĪŻ├┐ę╗▌å░³└©ā╔éĆļAČ╬Ż║┤žĄ─Į©┴óļAČ╬┼cöĄō■Ą─ĘĆČ©é„▌öļAČ╬ĪŻį┌┤žĄ─Į©┴óļAČ╬Ż¼═©▀^╦ŃĘ©ļSÖC▀xō±─│ą®╣سc│╔×ķ┤žŅ^Ż¼Ųõ╦¹╣سcät▀xō±┼cŲõŠÓļxūŅĮ³Ą─┤žŅ^ą╬│╔┤žŻ╗į┌öĄō■Ą─ĘĆČ©é„▌öļAČ╬Ż¼├┐éĆ╣سcĘųäe▓╔╝»ŽÓĻPöĄō■é„╦═ų┴┤žŅ^Ż¼┤žŅ^Įė╩š┤žā╚Ė„éĆ╣سcĄ─öĄō■║¾ę╗Ų░l╦═Įo╗∙šŠĪŻ
į┌┤žĄ─Į©┴óļAČ╬Ż¼ĻPµIå¢Ņ}Š═╩Ū┤žŅ^Ą─▀xō±ĪŻ×ķ┴╦▀xō±┤žŅ^Ż¼ŠWĮjā╚├┐éĆ╣سcČ╝ļSÖC╔·│╔ę╗éĆĮķė┌0Ī½1ų«ķgĄ─öĄn╚ń╣¹nąĪė┌T(n)Ż¼ätŲõ│╔×ķ┤žŅ^Ż¼T(n)Ą─ėŗ╦ŃĘĮĘ©╚ńŽ┬Ż║
ĪĪĪĪ
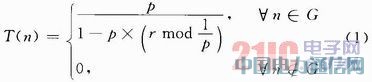
╩ĮųąŻ║p×ķŅAįOĄ─├┐éĆ╣سc│╔×ķ┤žŅ^Ą─Ė┼┬╩Ż╗r×ķ«öŪ░▀\ąąĄ─▌åöĄŻ╗G×ķūŅĮ³Ą─1Ż»p▌åųą╔ą╬┤│╔×ķ┤žŅ^Ą─╣سc╝»║ŽĪŻįō╦ŃĘ©ūī├┐1Ż»p▌åųąŠWĮjā╚Ą─Ė„éĆ╣سcČ╝ėąŪęāHėąę╗┤╬▌å│╔×ķ┤žŅ^ĪŻ═Ļ│╔┤žŅ^▀xō±ęį║¾Ż¼│╔×ķ┤žŅ^Ą─├┐éĆ╣سcČ╝Ž“ŠWĮj░l╦═ÅV▓źą┼ŽóŻ¼╚╗║¾ŠWĮjā╚Ą─├┐éĆ╣سc═©▀^╩šĄĮĄ─ą┼╠¢ÅŖČ╚øQČ©╦³ę¬╝ė╚ļĄ─┤ž(ą┼╠¢Ą─ÅŖČ╚┼cā╔éĆ╣سcų▒ĮėĄ─ŠÓļxš²ŽÓĻP)▓óŽ“įō┤žŅ^░l╦═šłŪ¾ą┼ŽóŻ¼ą╬│╔┤žĪŻĘų┤ž═Ļ│╔ų«║¾┤žŅ^╣سc▓╔ė├TDMAĘĮ╩Į×ķ┤žā╚Ą─├┐éĆ╣سcĘų┼õŲõŽ“┤žŅ^╔Žé„öĄō■Ą─ĢrŽČŻ¼ķ_╩╝öĄō■Ą─ĘĆČ©é„▌öļAČ╬Ż¼Įø▀^ę╗Č©Ģrķg║¾į┘ķ_╩╝Ž┬ę╗▌åĄ─裣hŻ¼ų▒ų┴╣سcę“─▄┴┐║─▒MĻæ└m╦└═÷Ż¼«ö╩ŻėÓ╣سc▓╗į┘ØMūŃöĄō■▓╔╝»Ą─ąĶę¬ĢrŻ¼ŠWĮjĄ─╔·├³ĮY╩°ĪŻ
LEACHģfūhĄ─Ęų┤ž═žōõĮYśŗ¤oąĶÅ═ļsĄ─┬Ęė╔ą┼ŽóŻ¼£p╔┘┴╦┬Ęė╔┐žųŲ▀^│╠ųąŽ¹║─Ą──▄┴┐Ż¼┤žā╚╣سc┤¾▓┐ĘųĢrķg┐╔ęįĻPķ]║──▄ūŅĖ▀Ą─═©ą┼─ŻēKŻ¼īóöĄō■▐D░l╣”─▄Į╗Įo┤žŅ^╣سcŻ¼ėąą¦Ąž╣Ø╩Ī┴╦┤žā╚╣سc─▄┴┐Ż¼Č°┤žŅ^Ą─▌åōQÖCųŲę▓▒ŻūC┴╦─│éĆ╣سcĄ──▄┴┐▓╗ų┴ė┌▀^┐ņŽ¹║─Ż¼ŽÓī”ŲĮ║Ō┴╦╦∙ėą╣سcĄ──▄║─Ż¼čėķL┴╦ŠWĮj╔·┤µĢrķgĪŻ
’@╚╗Ż¼LEACHģfūhę▓┤µį┌╚▒³cŻ¼ų„ę¬¾w¼Fį┌ęįŽ┬ā╔éĆĘĮ├µŻ║
(1)┤žŅ^▀xō±╦ŃĘ©Ą─ļSÖCąį▀^┤¾Ż¼į┌├┐▌åĄ─┤žŅ^▀xō±ļAČ╬Ż¼╚╬║╬╣سc│╔×ķ┤žŅ^Ą─Ė┼┬╩ŽÓ═¼Ż¼Č°┤žŅ^╣سc│ąō·┴╦ŠWĮjųąĄ─║▄┤¾▓┐Ęų═©ą┼Ż¼░³└©Å─┤žā╚╣سcĮė╩šöĄō■┼c░l╦═öĄō■ų┴╗∙šŠŻ¼«ö─▄┴┐▌^Ą═Ą─╣سc«ö▀x×ķ┤žŅ^Ģr▒ž╚╗Ģ■ī¦ų┬Ųõ─▄┴┐Ą─┐ņ╦┘║─╔óęįų┴╦└═÷Ż¼╣سc─▄┴┐Ą─▓╗ŲĮ║Ōę▓īóė░ĒæŠWĮjš¹¾wĄ─╔·┤µĢrķgŻ╗
(2)LEACHģfūhį┌öĄō■é„▌öųąļm╚╗¾w¼F┴╦öĄō■╚┌║ŽĄ─╦╝ŽļŻ¼Ą½▓ó╬┤╠ß│÷öĄō■╚┌║ŽĄ─Š▀¾w┤ļ╩®ĪŻ
2 ╗∙ė┌LEACHĄ─öĄō■╚┌║Ž╦ŃĘ©
ßśī”LEACHģfūhĄ─▓╗ūŃŻ¼▒Š╬─╠ß│÷┴╦ę╗ĘN╗∙ė┌LEACHĄ─öĄō■╚┌║Ž╦ŃĘ©Ż¼ų╝į┌┐╦Ę■LEACHĄ─▓╗ūŃ▓ó╝ė╚ļöĄō■╚┌║ŽÖCųŲŻ¼╣Ø╩ĪŠWĮj┘Yį┤Ż¼╠ß╔²öĄō■▓╔╝»ą¦┬╩ĪŻ
2Ż«1 ┤žŅ^▀xō±╦ŃĘ©
ę“×ķLEACHĄ─┤žŅ^▀xō±╦ŃĘ©ļSÖCąį▀^┤¾Ģ■ī¦ų┬▓┐Ęų╣سcĄ──▄┴┐Ž¹║─▀^┐ņŻ¼▒Š╦ŃĘ©į┌┤žŅ^▀xō±ÖCųŲ╔Ž╝ė╚ļ┴╦─▄┴┐┐žųŲę“╦žŻ¼ūī╩ŻėÓ─▄┴┐Ė▀Ą─╣سcėąĖ³┤¾Ą─Ė┼┬╩«ö▀x×ķ┤žŅ^ĪŻŠ▀¾wīŹ¼FĘĮĘ©╩Ū═©▀^╣سc«öŪ░╩ŻėÓ─▄┴┐┼cŲõ│§╩╝─▄┴┐Ą─▒╚ųĄüĒė░ĒæķōųĄT(n)Ż¼T(n)Ą─ėŗ╦ŃĘĮĘ©╚ńŽ┬Ż║
ĪĪĪĪ
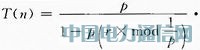
╩ĮųąŻ║En_current▒Ē╩Š╣سc«öŪ░Ą─╩ŻėÓ─▄┴┐Ż╗En_initial▒Ē╩Š╣سcĄ─│§╩╝─▄┴┐Ż╗rm▒Ē╩Š╣سc▀B└m╬┤«ö▀x×ķ┤žŅ^Ą─▌åöĄŻ¼├┐▌å▀Mąą┤žŅ^▀xō±Ģr╚¶įō╣سc«ö▀x×ķ┤žŅ^Ż¼ätrmųžų├×ķ0Ż¼Č°╚¶įō╣سc╬┤«ö▀x×ķ┤žŅ^Ż¼ätrmūįį÷ę╗┤╬ĪŻ
į┌┤žŅ^▀xō±╦ŃĘ©ųą╝ė╚ļ╔Ž╩÷─▄┴┐Ž▐ųŲę“╦ž║¾Ż¼╣سc«ö▀x×ķ┤žŅ^Ą─ļSÖCąį┤¾┤¾ĮĄĄ═Ż¼╩ŻėÓ─▄┴┐ČÓĄ─╣سc▒╚╩ŻėÓ─▄┴┐Ą═Ą─╣سcėąĖ³┤¾Ą─Äū┬╩«ö▀x×ķ┤žŅ^Ż¼ę“┤╦śO┤¾Ąž└¹ė├┴╦╣سcĄ─╩ŻėÓ─▄┴┐Ż¼ėąą¦Ę└ų╣┴╦─│ą®╣سc─▄┴┐Ž¹║─▀^┐ņęįų┬╦└═÷Ż¼ŲĮ║Ō┴╦ŠWĮjā╚╣سcĄ──▄┴┐Ž¹║─ĪŻ
2Ż«2 ┤žŅ^öĄō■╚┌║ŽśõĄ─Į©┴ó
ę└ō■LEACHī”¤oŠĆé„ĖąŲ„ŠWĮjĄ─╝┘įOŻ¼╣سc░l╦═ą┼ŽóĄ──▄║─ETx(kŻ¼d)┼cĮė╩šą┼ŽóĄ──▄║─ERx(k)Ęųäe×ķŻ║
ĪĪĪĪ
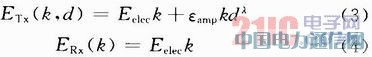
╩ĮųąŻ║Eelec×ķ░l╦═║═Įė╩šå╬╬╗ą┼ŽóĄ──▄║─Ż╗εamp×ķą┼╠¢░l╦═Ę┼┤¾Ų„Ž“å╬╬╗ŠÓļx░l╦═å╬╬╗ą┼ŽóĄ──▄║─Ż╗k×ķé„▌öĄ─ą┼Žó┴┐Ż╗d×ķą┼Žó░l╦═╣سc┼cĮė╩š╣سcķgĄ─ŠÓļxŻ╗λ×ķ┬ĘÅĮōp║─ųĖöĄĪŻ
ė╔╔Ž╩÷╣½╩Į┐╔ų¬Ż¼╣سc░l╦═ą┼ŽóŽ¹║─Ą──▄┴┐Ģ■ę“×ķŠÓļxĄ─į÷╝ėČ°┤¾Ę∙į÷╝ėŻ¼Č°į┌LEACHĄ─öĄō■é„▌öļAČ╬Ż¼┤žā╚Ė„╣سcīóöĄō■é„▌öĮo┤žŅ^ų«║¾┤žŅ^ų▒Įė┼c╗∙šŠ═©ą┼Ż¼▀@ļm╚╗║å▒ŃŻ¼Ą½╚¶┤žŅ^┼c╗∙šŠŠÓļx▀^▀hŻ¼öĄō■é„▌ö╦∙Ž¹║─Ą──▄┴┐īóĢ■║▄┤¾Ż¼×ķĮŌøQ▀@éĆå¢Ņ}Ż¼▒Š╬─īóį┌┤žŅ^╣سc┼c╗∙šŠĄ─═©ą┼ųą╝ė╚ļČÓ╠°Ą─öĄō■╚┌║ŽśõĪŻ
Š▀¾wīŹ¼FĘĮĘ©╩Ūį┌Ęų┤ž▀^│╠═Ļ│╔ų«║¾Ż¼┤žŅ^╣سcŽÓ╗ź░l╦═╠Į£yą┼Žó░³Ż¼║═╗∙šŠą╬│╔Ę┤Ž“ĮM▓źśõŻ¼įōśõĄ─ą╬│╔╦ŃĘ©ų„ę¬╗∙ė┌DDSPŻ¼į┌▒ŻūC┼c╗∙šŠ┬ĘÅĮūŅČ╠Ą─Ū░╠ߎ┬Ż¼▀xō±┼cęčėŗ╦ŃĄ──┐Ą─┤žŅ^ūŅĮ³Ą─┬ĘÅĮŻ¼═©▀^─┐Ą─┤žŅ^ų«ķg╣▓ŽĒ▒M┐╔─▄ķLĄ─┬ĘÅĮüĒĮĄĄ═╔·│╔śõĄ──▄┴┐Ž¹║─ĪŻĘ┤Ž“ĮM▓źśõą╬│╔ų«║¾Ż¼öĄō■╚┌║Ž▀^│╠▓╗āH─▄į┌┤žŅ^╠Ä└Ē┤žā╚╣سcé„╦═üĒĄ─öĄō■ĢrīŹ¼FŻ¼ę▓─▄į┌┤žŅ^ų«ķg═©▀^Ę┤Ž“ĮM▓źśõŽ“╗∙šŠ░l╦═öĄō■ĢrīŹ¼FŻ¼ūīöĄō■▓╔╝»ą¦┬╩Ė³Ė▀Ż¼═¼Ģr▒▄├Ō┴╦▀^▀hĄ─┤žŅ^ų▒ĮėŽ“╗∙šŠ░l╦═öĄō■Ģr«a╔·▀^Ė▀Ą──▄║─Ż¼┤╦ĢrŠWĮjĄ─═žōõĮYśŗ╚ńłD1╦∙╩ŠĪŻ
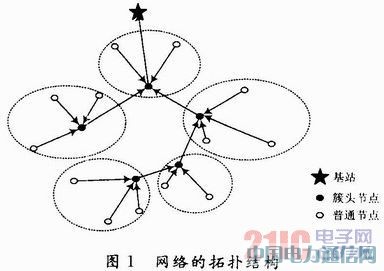
2Ż«3 öĄō■╚┌║Ž▓▀┬į
¤oŠĆé„ĖąŲ„ŠWĮjĄ─öĄō■╚┌║Ž▓╗āHāH╩Ūī”öĄō■▀Mąą║åå╬Ą─ŲĮŠ∙ĪóŪ¾║═Ą╚▀\╦ŃŻ¼Ė∙ō■Š▀¾wąĶŪ¾Ż¼ąĶę¬▓╔╚Ī▓╗═¼Ą─╚┌║Ž┤ļ╩®Ż¼öĄō■╚┌║ŽĄ─Ēśą“ę╗░Ń╩ŪÅ─öĄō■īėĄĮ╠žš„īėį┘ĄĮøQ▓▀īėĪŻ▒Šģfūhæ¬ė├ą┼Žóņž▀MąąöĄō■ĘųŅÉ╚┌║ŽŻ¼╣سcĖąų¬Ą─Ė„ĘNą┼ŽóĄ─öĄō■ĻPŽĄ┐╔═©▀^ą┼ŽóņžĄ─ėŗ╦ŃĘų×ķča│õöĄō■Īó╚▀ėÓöĄō■ęį╝░ø_═╗öĄō■ĪŻča│õöĄō■ųĖé„ĖąŲ„╣سcĖąų¬Ą──┐ś╦▓╗═¼╠žš„Ą─ą┼ŽóŻ╗╚▀ėÓöĄō■ųĖé„ĖąŲ„╣سcĖąų¬Ą──┐ś╦═¼ę╗╠žš„Ą─ą┼ŽóŻ╗ø_═╗öĄō■ųĖé„ĖąŲ„╣سcĖąų¬Ą─▓╗═¼─┐ś╦Ą─ą┼Žó╗“š▀╩Ū═¼ę╗─┐ś╦Ģr┐š▓╗ŽÓĻPĄ─ą┼ŽóŻ¼╗“š▀╩Ūé„ĖąŲ„╣╩šŽČ°╠ß╣®Ą─├¼Č▄ą┼ŽóĪŻ┼ąČ©ā╔éĆé„ĖąŲ„╣سc╠ß╣®Ą─ą┼ŽóĄ─öĄō■ĻPŽĄĘĮĘ©╚ńŽ┬Ż║
╝┘Č©╣سc1┼c╣سc2Ėąų¬öĄō■Ą─Ęų▓╝╠žąįĘ¹║Žpi(xŻ»xi)Ż¼Ųõųąi×ķé„ĖąŲ„╠¢1╗“2Ż¼x(x∈X)×ķĖąų¬Ą─ļSÖCöĄŻ¼xi×ķ╣سciĖąų¬Ą─öĄō■ųĄŻ╗╣سci║═╣سcjĄ─┬ō║ŽĘų▓╝×ķpij(xŻ»xiŻ¼xj)Ż¼ė╔ą┼ŽóņžĄ─Č©┴xŻ¼╣سci║═jĖąų¬öĄō■Ą─ūįņžhi(xi)┼c┬ō║Žņžhij(xiŻ¼xj)Ą─ėŗ╦Ń╚ńŽ┬Ż║
ĪĪĪĪ
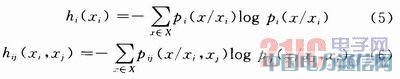
ūįņž▒Ē├„┴╦╣سciĖąų¬öĄō■xiĄ─▓╗┤_Č©ąįŻ¼Č°╗źņžät▒Ē├„┴╦╣سci║═j┬ō║ŽĖąų¬öĄō■(xiŻ¼xj)Ą─▓╗┤_Č©ąįĪŻ▒╚▌^hi(xi)Ż¼hj(xj)┼chij(xiŻ¼xj)╚²š▀Ą─┤¾ąĪĻPŽĄėąęįŽ┬╚²ĘNŪķørŻ║
(1)hi(xi)≤hij(xiŻ¼xj)≤hj(xj)Ż¼šf├„ā╔éĆé„ĖąŲ„Ą─┬ō║ŽĖąų¬öĄō■╝╚ø]£p╔┘xiĄ─▓╗┤_Č©ąįŻ¼ę▓ø]į÷╝ėxjĄ─▓╗┤_Č©ąįŻ¼ā╔éĆ╣سcĄ─Ėąų¬öĄō■╗ź▓╗ė░ĒæŻ¼ę“┤╦ā╔éĆöĄō■╩Ū╗źčaĄ─Ż╗
(2)hij(xiŻ¼xj)ĪĪĪĪ(3)hi(xi)≤hj(xj)
3 Ę┬šµīŹ“×
▒Š╬─▓╔ė├MatlabĮ©┴óĘ┬šµ─Żą═Ż¼Ęųäeī”įŁLEACH╦ŃĘ©┼cĖ─▀M║¾Ą─╦ŃĘ©▀MąąĘ┬šµĘų╬÷▓ó╝ėęį▒╚▌^ĪŻ
3Ż«1 Ę┬šµ─Żą═┼cģóöĄįOų├
▒ŠīŹ“×▓╔ė├LEACHČ©┴xĄ─╬’└Ē─Żą═Ż¼ŲõČ©┴x╚ńŽ┬Ż║
(1)╦∙ėą╣سcī┘ąį═Ļ╚½ę╗śėŻ¼─▄┴┐ėąŽ▐▓óŪęŠ∙─▄┼c╗∙šŠų▒Įė═©ą┼Ż╗
(2)╗∙šŠ╬╗ų├╣╠Č©Ż¼╣سc▓╗ų¬Ą└Ųõūį╔Ē╬╗ų├ą┼ŽóŻ╗
(3)¤oŠĆ═©ą┼▓╔ė├ī”ĘQĄ─ą┼Ą└Ż¼Ž¹║─Ą──▄┴┐┼cé„▌öĄ─ĘĮŽ“¤oĻPŻ¼╣سc┐╔Ė∙ō■┼c─┐ś╦╣سcĄ─ŠÓļxüĒš{╣Ø╔õŅl░l╔õ╣”┬╩Ż╗
(4)┤žŅ^╣سc┐╔ł╠ąąöĄō■╚┌║ŽĪŻ
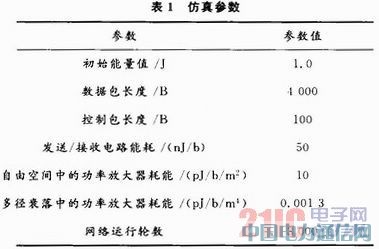
īŹ“×▓╔ė├Ą─Ė„ģóöĄČ©┴x╚ń▒Ē1╦∙╩ŠĪŻ
3Ż«2 Ę┬šµĮY╣¹╝░Ęų╬÷
╦ŃĘ©Ą─Ę┬šµ▓╔ė├┴╦300éĆ╣سcŻ¼ļSÖCĘų▓╝į┌500×500Ą─ŲĮ├µģ^ė“Ż¼Č°╗∙šŠ╬╗ų├×ķ(250Ż¼250)ĪŻ╣سcĘų▓╝╩ŠęŌ╚ńłD2╦∙╩ŠĪŻ

łD2ųą“*”▒Ē╩Šé„ĖąŲ„╣سcŻ¼“ĪŅ”▒Ē╩Š╗∙šŠĪŻĮ©┴ó╔Ž╩÷─Żą═║¾Ż¼LEACHģfūhĄ─Ę┬šµĮY╣¹╚ńłD3╦∙╩ŠĪŻ
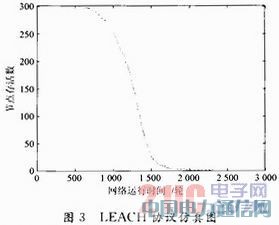
Ė─▀M║¾Ą─ģfūhĘ┬šµĮY╣¹╚ńłD4╦∙╩ŠĪŻ
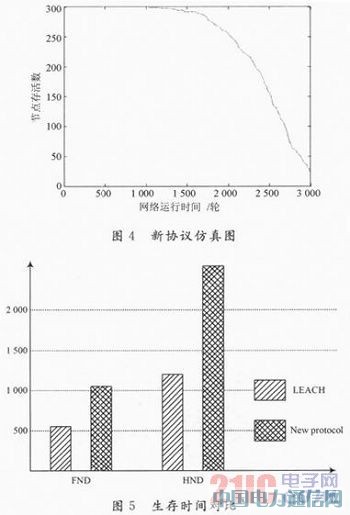
═©▀^▒╚▌^┐╔ęį├„’@ĄžĄ├│÷Ż¼ą┬ģfūh▒╚įŁLEACHģfūhŠ▀ėą║▄ķLĄ─ŠWĮj╔·┤µĢrķgĪŻ×ķ┴╦Ė³┴┐╗»Ąž▒╚▌^ā╔éĆģfūhĄ─ŠWĮjąį─▄Ż¼Ž┬├µ└^└mī”ŠWĮj▀\ąąųąĄ┌ę╗éĆ╣سcĄ─╦└═÷Ģrķg(First Node DeadŻ¼FND)ęį╝░ę╗░ļ╣سcĄ─╦└═÷Ģrķg(Half Nocles DeadŻ¼HND)▀Mąą▒╚▌^Ż¼ę“×ķį┌Ęų┤ž┬Ęė╔ųąŻ¼▒žĒÜę¬ę╗éĆęį╔ŽĄ─╣سc▓┼─▄▀Mąą┬Ęė╔ėŗ╦ŃŻ¼╦∙ęįį┌┤╦▓╗┐╝æ]╚½▓┐╣سcĄ─╦└═÷ĢrķgĪŻė╔ė┌Ę┬šµīŹ“ץ─ļSÖCąįŻ¼├┐éĆģfūhĄ─FND┼cHNDųĄ╩Ūī”ā╔éĆģfūh▀MąąČÓ┤╬▀\╦Ń║¾╚ĪĄ─ŲĮŠ∙ųĄĪŻ╚ńłD5╦∙╩ŠĪŻ
ė╔łD5┐╔ų¬Ż¼ī”ė┌FNDŻ¼ą┬ģfūh▒╚įŁLEACHģfūhčėķL┴╦ŠWĮj╔·┤µĢrķg╝s85ŻźŻ¼Č°ī”ė┌HNDŻ¼ą┬ģfūhät▒╚įŁLEACHģfūhčėķL┴╦╝s100ŻźĪŻŠC╔Ž╦∙╩÷Ż¼ė╔ė┌ą┬╦ŃĘ©Ą─ųTČÓĖ─▀MŻ¼ŠWĮjĄ─š¹¾wąį─▄▒╚LEACHĖ³×ķā׹ŃĪŻ
4 ĮYšZ
▒Š╬─═©▀^ī”LEACHį┌┤žŅ^▀xō±ÖCųŲęį╝░öĄō■╚┌║ŽĘĮ├µ▓╗ūŃų«╠ÄĄ─Ė─▀MŻ¼╠ß│÷┴╦ę╗ĘNą┬Ą─╗∙ė┌LEACHĘų┤ž┬Ęė╔ģfūhĄ─öĄō■╚┌║Ž╦ŃĘ©Ż¼Ė─▀Mų„ę¬¾w¼Fį┌╚²éĆĘĮ├µŻ╗į┌┤žŅ^▀xō±╦ŃĘ©╔Ž╝ė╚ļ┴╦─▄┴┐┐žųŲÖCųŲŻ¼ūī╩ŻėÓ─▄┴┐Ė▀Ą─╣سcėąĖ³Ė▀Äū┬╩«ö▀x×ķ┤žŅ^Ż╗īó┤žŅ^╣سcĄĮ╗∙šŠĄ─å╬╠°┬Ęė╔Ė─×ķ╝ė╚ļ┴╦öĄō■╚┌║Ž▓▀┬įĄ─Ę┤Ž“ĮM▓źśõŻ¼╣Ø╩Ī┴╦┼c╗∙šŠ▀^▀hĄ─┤žŅ^Ž¹║─Ą──▄┴┐Ż¼öĄō■į┌▓╗öÓ═∙╗∙šŠĄ─é„▌öųąę▓ėąĖ³ČÓĄ─ÖCĢ■╚┌║ŽŻ╗╠ß│÷┴╦╗∙ė┌ą┼ŽóņžĄ─Š▀¾wöĄō■╚┌║Ž▓▀┬įŻ¼ūīą┼ŽóĄ─é„▌öĖ³ėąą¦┬╩ĪŻĘ┬šµĮY╣¹▒Ē├„Ż¼▀@ą®Ė─▀Mėąą¦ŲĮ║Ō┴╦╣سc─▄┴┐Ž¹║─Ż¼čėķL┴╦ŠWĮj╔·┤µĢrķgĪŻ