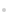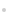ЈЁЦРҮшГсәҪҙуҢWУӢЛгҷCҝЖҢWЕcјјРgҢWФәЈ¬МмҪт 300300Ј©
0 ТэСФ
өГТжУЪӮчёРЖчј°ұOҝШјјРgөДЯMІҪЈ¬¬Fҙъ№ӨҳIФOӮдөДЙъ®aЯ\РР о‘BәНЯ\РРӯhҫіДЬүтұ»ҢҚ•rУӣдӣәНёРЦӘЈ¬·eАЫІў®aЙъБЛәЈБҝ¶аҫS•rйgРтБРЈЁMTS,multivariate time seriesЈ©”ө“ю[1]ЎЈАэИзЈ¬ФЖ·ю„ХЖчөДCPUАыУГВКЎўғИҙжХјУГВКЎўҫWҪjБчБҝөИұOңy”ө“юЈ¬әҪҝХЖчөДЛЩ¶ИЎўёЯ¶ИЎўё©СцҪЗ¶ИөИӮчёРЖч”ө“юЈ¬·ҙУіәҪМмЖчЯ\РР о‘BөДЯbңyРЕМ–Ј¬№ӨҸSЙъ®aҷCЖчөДңШ¶ИЎўЮDЛЩөИұOңy”ө“юЎЈЯ@Р©MTS ”ө“юөД®җіЈИЎЦөЖ¬¶ОНщНщТвО¶ЦшФOӮд№КХПЎўІЩЧчИЛҶTК§Х`өИМШКвЗйӣrөД°lЙъЈ¬ТІҝЙДЬұнКҫЙъ®aӯhҫіЦРҙжФЪл[РФ°ІИ«л[»јЎЈЯ@Р©®җіЈИзІ»ДЬұ»УРР§ЧR„eЈ¬әЬҝЙДЬФміЙҪӣқъ“pК§ЎЈ№ӨҳIоIУтMTS ”ө“юУРИзПВМШьcЈәуwБҝҙуЎўЯBАmІЙҳУЎўғrЦөГЬ¶ИөНЎў„У‘BРФҸҠЈ»MTS ёчҫS¶ИЦ®йgҫЯУРҸНлsөД•rҝХсоәПкPПөЈ»№ӨҳIФOӮдНЁЯ^ЖдЬӣјюҝШЦЖЯүЭӢНщНщЕcЖдЯ\РРӯhҫіЎўІЩЧчИЛҶTј°ПакPФOӮдПөҪyУРҸНлsҪ»»ҘЈ¬·ҙУіЖдЯ\РР о‘BөДMTS ИЎЦөҫЯУРлSҷCРФ[2]ЎЈБнНвЈ¬УЙУЪ№ӨҳIоIУтMTS ®җіЈҳУұҫПаҢҰЭ^ЙЩЎўҳЛЧў®җіЈҙъғrЭ^ёЯЈ¬СРҫҝХЯҙу¶акPЧў»щУЪҹoұO¶ҪөДMTS®җіЈҷzңy·Ҫ·ЁЎЈӮчҪyөДЦчіЙ·Ц·ЦОцЎўёЯЛ№»мәПДЈРНЎўТ»оҗЦ§іЦПтБҝҷCөИҷCЖчҢWБ•·Ҫ·Ёҹo·ЁәЬәГөШҪЁДЈ№ӨҳIоIУтMTS ”ө“юөДҸНлsРФЩ|ЎЈУЙУЪЙо¶ИҢWБ•ҸҠҙуөД”ө“юұнХчДЬБҰЈ¬ҪьДкҒнЈ¬»щУЪЙо¶ИҢWБ•өДҹoұO¶ҪMTS ®җіЈҷzңyСРҫҝөГөҪБЛҸV·әкPЧўЎЈMTS ®җіЈҷzңy°ьАЁРтБРјүәНЛІ•rјү®җіЈ°l¬FЎЈРтБРјү®җіЈ[3-5]КЗЦёMTS ҳУұҫХыӮҖРтБР»тЖдЧУРтБР…^„eУЪ¶а”өҳУұҫЎЈЛІ•rјү®җіЈКЗЦёФЪДіӮҖ•rйgьc»т¶М•rйgҙ°ғИөД®җіЈЎЈұҫОДДЈРНҢЩУЪЛІ•rјү®җіЈҷzңyДЈРНЎЈ
ҮъА@ИзәОҪЁДЈ№ӨҳIоIУтMTS •rРтТАЩҮРФәНлSҷCРФЈ¬СРҫҝХЯМбіцБЛТ»Р©Йо¶ИҢWБ•ДЈРН[2,6-10]ЎЈЯ@Р©ДЈРНөДУ–ҫҡДҝҳЛҫщһйҢWБ•ХэіЈMTS ҳУұҫјҜөД•rРт·ЦІјЎЈЖдЦРЈ¬ҙуІҝ·Ц·Ҫ·ЁҫщҪYәПСӯӯhЙсҪӣҫWҪjЈЁRNN,recurrent neural networkЈ©әНЧғ·ЦЧФҫҺҙaЖчЈЁVAE,variational autoencoderЈ©ҪЁДЈMTS ”ө“юөД•rРтТАЩҮРФәНлSҷCРФЎЈө«ТСУРДЈРНҙжФЪИзПВҶ–о}ЎЈ
1) ІЙУГRNN өДл[ПтБҝҢҚ¬FVAE л[ҝХйgЦРлSҷCЧғБҝйgөД•rРтТАЩҮРФЈ¬И»¶шRNN лyТФІ¶«@РтБР”ө“юөДйL•rТАЩҮРФЈ¬Я@ҪөөНБЛҢWБ•РтБР”ө“ю·ЦІјөДДЬБҰЎЈ
2) УӢЛглSҷCЧғБҝөДҪьЛЖәутһ·ЦІјәНПИтһ·ЦІјөДҫWҪjҪYҳӢПаН¬Ј¬Я@К№2 ·N·ЦІјKL Йў¶ИЈЁKullback-Leibler divergenceЈ©ҫалxЭ^РЎЈ¬ФцјУБЛДЈРНөДУ–ҫҡлy¶ИЎЈ»щУЪҫҖРФёЯЛ№ о‘BҝХйgДЈРНЈЁLGSSM,linear Gaussian state space modelЈ©УӢЛглSҷCЧғБҝөДПИтһ·ЦІјҹo·ЁҢҚ¬FлSҷCЧғБҝйgөД·ЗҫҖРФЮD“QЎЈ
3) »щУЪRNN өДЙъіЙҫWҪjғHТАЩҮУЪлSҷCЧғБҝөДІЙҳУЦөЈ¬ӣ]УРАыУГRNN НЖ”аҫWҪjөДҙ_¶ЁРФл[ПтБҝЎЈ
бҳҢҰТФЙПҶ–о}Ј¬ұҫОДМбіцТ»·NГжПт№ӨҳIоIУтMTS ®җіЈҷzңyөДлSҷCTransformerЈЁST-MTS-AD,stochastic Transformer for MTS anomaly detectionЈ©ДЈРНЎЈФ“ДЈРНУЙTransformer ҫҺҙaЖчЭ”іцөДұнКҫёч•rҝМMTS йL•rТАЩҮМШХчәНЙПТ»•rҝМлSҷCЧғБҝөДІЙҳУЦөЙъіЙ®”З°•rҝМлSҷCЧғБҝөДҪьЛЖәутһ·ЦІјЈ¬К№ST-MTS-AD ҝЙҪиУГTransformer ҫҺҙaЖчЭ”іцөДйL•rТАЩҮМШХчФЪл[ҝХйgЦРӮчІҘлSҷCЧғБҝйgөДйL•rТАЩҮРФЈ¬ІЙУГйTҝШЮD“QәҜ”өЈЁGTF,gated transition functionЈ©ЙъіЙлSҷCЧғБҝөДПИтһ·ЦІјІўҢҚ¬FлSҷCЧғБҝйgөД·ЗҫҖРФЮD“QЈ¬НЁЯ^ҢўTransformer ҫҺҙaЖчЭ”іцөДйL•rТАЩҮМШХчәНлSҷCЧғБҝІЙҳУЦөЭ”Ил¶аҢУёРЦӘЖчЈЁMLP,multilayer perceptronЈ©ЦШҳӢMTS ёч•rҝМИЎЦө·ЦІјЎЈФЪ4 ӮҖ№ӨҳIоIУт№«й_MTS ”ө“юјҜЙПөДҢҚтһұнГчST-MTS-AD ҫЯУРЭ^әГөД®җіЈҷzңyР§№ыЎЈ
1 ПакPСРҫҝ¬F о
¶аҫS•rйgРтБР®җіЈҷzңyКЗ•rйgРтБР·ЦОцоIУтЦРөДЦШТӘИО„ХЦ®Т»Ј¬ЦјФЪҢӨХТІ»·ыәПТҺ„tөД»тіц¬FЖ«ІоөДРтБРЖ¬¶О[11]ЎЈДҝЗ°Ј¬»щУЪЙо¶ИҢWБ•өДMTSЛІ•rјү®җіЈҷzңy·Ҫ·ЁИзПВЎЈ
1) »щУЪоAңyәНЦШҳӢөДҙ_¶ЁРФ·Ҫ·ЁЎЈHundmanөИ[12]ФOУӢБЛ»щУЪйL¶М•rУӣ‘ӣЈЁLSTM,long short-term memoryЈ©ҫWҪjөДәҪМмЖчЯbңyРЕМ–®җіЈҷzңy·Ҫ·ЁЈ¬НЁЯ^оAңyХ`Іоҙ_¶Ё®җіЈЈ¬ЖдЯҖМбіцБЛТ»·N·З…ў”ө„У‘B®җіЈҷzңyй“Цөҙ_¶Ё·Ҫ·ЁЈ¬ДЬФЪХ`ҲуВКәНВ©ҲуВКЦ®йgЯ_өҪЖҪәвЎЈZhang өИ[13]МбіцБЛГжПт¶аӮчёРЖчMTS ®җіЈҷzңyөДЙо¶Иҫн·eЧФҫҺҙaУӣ‘ӣҫWҪjЈ¬ҢўMTS өД•rҝХЗ¶ИлұнКҫәНЦШҳӢХ`ІоЭ”ИлҫҖРФЧФ»ШҡwДЈРНәН»щУЪЧўТвБҰҷCЦЖөДлpПтLSTM ҫWҪjЈ¬УЙЦШҳӢ“pК§әНоAңy“pК§ҙ_¶ЁMTS ®җіЈЎЈMalhotra өИ[14]МбіцБЛТ»·N»щУЪLSTM өДЧФҫҺҙaЖчДЈРНЈ¬ЦјФЪЦШҪЁХэіЈ•rйgРтБРЈ¬К№УГЦШҳӢХ`ІоЯMРР®җіЈҷzңyЎЈZhangөИ[15]МбіцБЛТ»·N¶аіЯ¶Иҫн·eСӯӯhЧФҫҺҙaЖчЈЁMSCREDЈ©Ј¬КЧПИҳӢҪЁДЬұнХчMTS І»Н¬ЧғБҝйgПакPРФөД¶аіЯ¶ИәһГыҫШкҮЈ»И»әуІЙУГҫн·eҫҺҙaЖчҢҰәһГыҫШкҮЯMРРҫҺҙaЈ¬К№УГ»щУЪЧўТвБҰөДҫн·eLSTM І¶«@MTS •rРтТАЩҮРФЈ»Чоәу»щУЪҫн·eҪвҙaЖчЦШҪЁәһГыҫШкҮЈ¬ІўАыУГәһГыҫШкҮөДЦШҳӢХ`ІоФ\”а®җіЈЎЈAudibert өИ[16]ФOУӢБЛ°ьә¬Т»ӮҖҫҺҙaЖчәН2 ӮҖҪвҙaЖчөДЧФҫҺҙaЖчҫWҪjҪYҳӢЈ¬ІЙУГҢҰҝ№ҢWБ•ІЯВФУ–ҫҡҫWҪjЈ¬ұЬГвЧФҫҺҙaЖчҹo·ЁНЁЯ^ЦШҳӢХ`Іо…^·ЦХэіЈҳУұҫЕc®җіЈҳУұҫөД¬FПуЈ¬Ф“·Ҫ·Ёӣ]УРК№УГСӯӯhЙсҪӣҫWҪjҸД¶ш«@өГБЛЭ^ҝмөДУ–ҫҡР§ВКЈ¬ө«ҹo·ЁҪЁДЈMTS өД•rРтТАЩҮкPПөЎЈЙПКц·Ҫ·ЁТФоAңy»тЦШҳӢһйУ–ҫҡДҝҳЛҝМ®ӢХэіЈMTS ҳУұҫөДМШХчЈ¬УЙЦШҳӢХ`ІоәНоAңyХ`ІоҷzңyMTS ®җіЈЈ¬ҹo·ЁҪЁДЈMTS өДлSҷCРФЎЈ
2) »щУЪЦШҳӢөДлSҷCРФ·Ҫ·ЁЎЈZong өИ[6]МбіцТ»·NУГУЪҹoұO¶Ҫ®җіЈҷzңyөДЙо¶ИЧФҫҺҙaёЯЛ№»мәПДЈРНЈЁDAGMM,deep autoencoding Gaussian mixture modelЈ©Ј¬НЁЯ^ЧФҫҺҙaЖч«@өГУ–ҫҡҳУұҫөДөНҫSұнКҫЈ¬ҢўөНҫSұнКҫәНҳУұҫЦШҳӢХ`ІоЖҙҪУРОіЙөДПтБҝЭ”ИлУГҒнУ–ҫҡGMM …ў”өөД№АУӢҫWҪjЈ¬УЙGMM ДЈРНУӢЛгөДҳУұҫДЬБҝЦөҙ_¶ЁҳУұҫКЗ·с®җіЈЎЈDeng өИ[7]ІЙУГҲDҫн·eҫWҪjІ¶«@MTS ЧғБҝйgҪ»»ҘМШХчЈ¬УЙЧФЧўТвБҰҷCЦЖМбИЎMTS йL•rТАЩҮМШХчЈ¬»щУЪVAE өДЦШҳӢДЬБҰЯMРРMTS ®җіЈҷzңyЎЈPark өИ[8]МбіцБЛ»щУЪLSTM әНVAE өД¶аДЈ‘BMTS ®җіЈҷzңy·Ҫ·ЁЈ¬ТФLSTM ҫWҪjҪYҳӢЧчһйVAE ЦРөДЙъіЙҫWҪjәННЖ”аҫWҪjұнКҫMTS өДлSҷCРФәН•rРтТАЩҮРФЎЈОД«I[7-8]НЁЯ^ЧФЧўТвБҰҷCЦЖ»тRNN І¶«@MTS өД•rРтТАЩҮРФЈ¬ІўЗТГҝӮҖ•rйgьcНЁЯ^ЦШ…ў”ө»ҜІЙҳУөГөҪөДлSҷCЧғБҝҫЯУРлSҷCРФЈ¬ө«лSҷCЧғБҝЦ®йgӣ]УР•rРтТАЩҮРФЎЈ
һйҙЛЈ¬СРҫҝХЯМбіцБЛ»щУЪVAE өДРтБР”ө“юЙъіЙДЈРН[17-19]Ј¬Я@Р©·Ҫ·ЁҫщІЙУГЧғ·ЦНЖ”ајјРgҢWБ••rРт”ө“ю·ЦІјЈ¬ІўЗТҝЙТФұнКҫлSҷCЧғБҝйgөД•rРтТАЩҮРФЎЈChung өИ[18]МбіцТ»·NЧғ·ЦСӯӯhЙсҪӣҫWҪjЈЁVRNN,variational recurrent neural networkЈ©ДЈРНЎЈVRNNөДНЖ”аҫWҪjУЙ•rРт”ө“ю®”З°•rҝМЭ”ИлЦөәНЙПТ»•rҝМRNN л[ПтБҝЙъіЙ®”З°•rҝМлSҷCЧғБҝөДҪьЛЖәутһ·ЦІјЎЈVRNN НЁЯ^RNN л[ПтБҝөДөьҙъёьРВҢҚ¬FлSҷCЧғБҝйgөД•rРтТАЩҮРФЎЈVRNN өДЙъіЙҫWҪjУЙ®”З°•rҝМлSҷCЧғБҝІЙҳУЦөәНЙПТ»•rҝМRNN л[ПтБҝЙъіЙ•rРт”ө“юИЎЦө·ЦІјЎЈDai өИ[9]МбіцБЛГжПтғИИЭ·Ц°lҫWҪjПөҪy¶аФӘкPжIРФДЬЦёҳЛ•rРт”ө“юөД®җіЈҷzңy·Ҫ·ЁSDFVAEЈЁstatic and dynamic factorized VAEЈ©Ј¬ҢўVRNN ЦРөДлSҷCЧғБҝ·ЦҪвһй„У‘BәНмo‘BлSҷCЧғБҝЈ¬ЖдЦРЈ¬мo‘BлSҷCЧғБҝҝМ®ӢғИИЭ·Ц°lҫWҪjПөҪyРФДЬЦёҳЛИЎЦөөД•rРтІ»ЧғРФЎЈSDFVAE УЙлpПтLSTMҫWҪjҢWБ•мo‘BлSҷCЧғБҝөДҪьЛЖәутһ·ЦІјЈ¬„У‘BлSҷCЧғБҝөДҪьЛЖәутһ·ЦІјЙъіЙ·ҪКҪЕcVRNN ПаН¬ЎЈLiөИ[10]МбіцБЛ»щУЪVRNN өДMTS ®җіЈҷzңy·Ҫ·ЁЈ¬ФЪ“pК§әҜ”өЦРТэИлК№ПааҸ•rҝМьc•rРтИЎЦөЙъіЙ·ЦІјПаҪьөДХэ„t»Ҝн—Ј¬К№ДЈРНҫЯУРёьәГөДҝ№ФлДЬБҰЎЈFraccaro өИ[19]МбіцБЛТ»·NИЪәП о‘BҝХйgДЈРНЈЁSSM,state space modelЈ©әНRNN өДлSҷCСӯӯhЙсҪӣҫWҪjЈЁSRNN,stochastic recurrent neural networkЈ©ЎЈSRNNДЈРННЁЯ^ТАЩҮУЪRNN л[ПтБҝәНSSM лSҷCЧғБҝІЙҳУЦөөДЙсҪӣҫWҪjҢҚ¬FSSM лSҷC о‘BЦ®йgөД·ЗҫҖРФЮD“QЈ¬К№SSM ҝЙТФАыУГRNN ұнКҫ•rРтТАЩҮкPПөөДл[ПтБҝФЪл[ҝХйgЦРӮчІҘлSҷCРФЎЈSRNN ЕcVRNN өД…^„eФЪУЪRNN л[ПтБҝөДёьРВІ»ТАЩҮУЪёч•rҝМөДлSҷCЧғБҝЈ¬ДЬЦұҪУҪЁДЈГҝӮҖ•rҝМлSҷCЧғБҝйgөД•rРтТАЩҮРФЈ¬ҢҚ¬FБЛRNN ҙ_¶ЁРФл[ЧғБҝәНSSM лSҷCЧғБҝөД·ЦлxЎЈОД«I[19]ұнГчSRNN ДЬүтұИVRNN ёьәГөШҢWБ••rРт”ө“юөД·ЦІјЎЈSu өИ[2]Мбіц»щУЪSRNN өДMTS®җіЈҷzңyДЈРНЈ¬Ф“ДЈРНөДНЖ”аҫWҪjҪYҳӢЕcSRNN ПаН¬Ј¬ФЪҙЛ»щөAЙПІЙУГЖҪГжҡwТ»»ҜБчјјРgҢWБ•ёч•rҝМ·ЗёЯЛ№·ЦІјөДҪьЛЖәутһ·ЦІјЎЈФЪЙъіЙҫWҪjЦРЈ¬Ф“ДЈРНУЙТАЩҮУЪлSҷCЧғБҝІЙҳУЦөөДRNN ЙъіЙ•rРт”ө“юИЎЦө·ЦІјЈ¬ІЙУГLGSSM УӢЛглSҷCЧғБҝөДПИтһ·ЦІјІўҢҚ¬FлSҷCЧғБҝйgөД•rРтТАЩҮРФЎЈ
2 ST-MTS-AD ДЈРНФOУӢ
2.1 ПакP·ыМ–¶ЁБxј°ST-MTS-AD ҫWҪjҪYҳӢ
MTS ”ө“юјҜУӣһйk=[k1,k2,Ўӯ,kN] ЎКRMЎБNЈ¬NһйkөДіЦАm•rйgйL¶ИЈ¬ГҝӮҖУ^ңyЦөkҰУЎКRMКЗФЪ•rйgьcҰУ(ҰУЎЬN)өДMҫSПтБҝЎЈК№УГҙ°ҝЪҙуРЎһйwЎў»¬„УІҪ·щһйlөД»¬„Уҙ°ҝЪҢҰkЯMРРоAМҺАнЈ¬ГҝӮҖ»¬„Уҙ°ҝЪһй
ұҫОДФOУӢөДST-MTS-AD ДЈРН»щУЪVAE өДЧғ·ЦНЖ”ајјРgҢWБ•MTS •rРт·ЦІјЈ¬ЖдЦчТӘғһ„ЭФЪУЪК№УГTransformer ҫҺҙaЖчЦРөД¶ао^ЧФЧўТвБҰҷCЦЖЙъіЙMTSёчӮҖ•rҝМьcөДлSҷC·ЦІјЈ¬ҢҚ¬FБЛVAE л[ҝХйgЦРлSҷCЧғБҝйgөДйL•rТАЩҮкPВ“ЎЈ¶шЗТST-MTS-AD өДЙъіЙҫWҪjһйMLPЈ¬ҪөөНБЛДЈРНөДҸНлsРФЎЈST-MTS-AD ДЈРНҪYҳӢИзҲD1 ЛщКҫЎЈФЪНЖ”аҫWҪjЦРЈ¬Transformer ҫҺҙaЖчҢўУ^ңyРтБРx1:TЎКRPЎБTУіЙдһйМШХчe1:T=[e1,Ўӯ,et,Ўӯ,eT] ЎКRdЎБTЈ¬dһйTransformer ҫҺҙaЖчЭ”іцҫS¶ИЈ¬e1:TІ¶«@x1:TЦРУ^ңyЧғБҝxtйgөДйL•rТАЩҮРФЈ¬et(1 ЎЬtЎЬT)ұнКҫe1:TФЪt•rҝМөДИЎЦөПтБҝЎЈҢўt-1 •rҝМлSҷCЧғБҝzt-1өДІЙҳУЦөәНetҙ®ҪУәуЭ”ИлMLP ЙъіЙt•rҝМлSҷCЧғБҝztөДҪьЛЖәутһ·ЦІјЈ¬ҢҚ¬FлSҷCЧғБҝzt-1әНztөД·ЗҫҖРФЮD“QәН•rРтТАЩҮкPВ“ЎЈУӣTӮҖлSҷCЧғБҝz1,Ўӯ,zTһйz1:TЎЈФЪЙъіЙҫWҪjЦРЈ¬t•rҝМлSҷCЧғБҝztІЙҳУЦөәНИЎЦөПтБҝetЭ”ИлMLP ЙъіЙөДИЎЦө·ЦІјЎЈTӮҖ•rҝМУ^ңyЧғБҝxtөДЦШҳӢЦө,Ўӯ,ұнКҫһйЎЈt-1 •rҝМлSҷCЧғБҝzt-1өДІЙҳУЦөЭ”ИлGTFЙъіЙt•rҝМлSҷCЧғБҝztөДПИтһ·ЦІјЈ¬z0һйлSҷCіхКј»ҜөДПтБҝЎЈST-MTS-AD НЁЯ^Чоҙу»ҜЧC“юПВҪзғһ»ҜНЖ”аҫWҪjәНЙъіЙҫWҪj…ў”өЈ¬УЙёч•rҝМxЎдtөДЦШҳӢёЕВКЛЖИ»ҙ_¶Ёx1:T®җіЈЖ¬¶ОЎЈ
2.2 ST-MTS-AD НЖ”аҫWҪjФOУӢ
Transformer ҫWҪjЦРөДЧФЧўТвБҰҷCЦЖИЭТЧІ¶«@РтБР”ө“юЦРйL•rТАЩҮМШХчЈ¬ОД«I[20]»щУЪTransformer ҫҺҙaЖчФOУӢБЛMTS өДёЯЩ|БҝұнКҫҢWБ•ДЈРНЎЈST-MTS-AD ДЈРНҢўTransformer ҫҺҙaЖчЧчһйVAE өДНЖ”аҫWҪjЈ¬І¶«@У^ңyРтБРx1:TЦРёчУ^ңyЧғБҝxtйgөДйL•rТАЩҮРФЎЈһйБЛҢҚ¬FлSҷCЧғБҝzt-1әНztөД·ЗҫҖРФЮD“QәН•rРтТАЩҮкPВ“Ј¬Ңўt-1 •rҝМлSҷCЧғБҝzt-1өДІЙҳУЦөәНTransformer ҫҺҙaЖчФЪt•rҝМөДЭ”іцetҙ®ҪУәуЙъіЙt•rҝМлSҷCЧғБҝztЎЈНЖ”аҫWҪjөДДҝҳЛКЗҢWБ•лSҷCЧғБҝz1:TөДХжҢҚәутһ·ЦІјЈ¬ST-MTS-ADНЁЯ^НЖ”аҫWҪjөГөҪz1:TөДҪьЛЖәутһ·ЦІјЈ¬ИзКҪ(1)ЛщКҫЎЈ
ST-MTS-AD ДЈРННЖ”аҫWҪjҪYҳӢИзҲD2 ЛщКҫЈ¬јҙКҪ(1)ЦРt•rҝМҪьЛЖәутһ·ЦІјҫWҪjҪYҳӢЎЈ
ҲD2 ST-MTS-AD ДЈРННЖ”аҫWҪjҪYҳӢ
e1:TУӢЛгЯ^іМИзПВЎЈ°ҙКҪ(2)ҢҰx1:TЯMРРО»ЦГҫҺҙaЈ¬ҫҺҙaҪY№ыУӣһйЎЈ
ЖдЦРЈ¬WxЎКRdЎБPһйҫWҪj…ў”өЈ»bЎКR1ЎБTһйЖ«ЦГн—Ј»wpЎКRdЎБTһйО»ЦГҫҺҙaҫШкҮЈ¬УЙХэПТәҜ”өФЪЕј”өО»ЦГУӢЛгөГөҪөДО»ЦГРЕПўәНУаПТәҜ”өФЪЖж”өО»ЦГУӢЛг«@өГөДО»ЦГРЕПўҪYәПРОіЙЈ¬ҫЯуwРОКҪИзПВ
УЙКҪ(4)Ў«КҪ(10)ЛщКҫөД¶ао^ЧўТвБҰҷCЦЖУӢЛгx1:TЦРУ^ңyЧғБҝйgйL•rТАЩҮМШХчe1:TЎЈ
2.3 ST-MTS-AD ЙъіЙҫWҪjФOУӢ
ST-MTS-AD ЙъіЙҫWҪjУЙMLP ҳӢіЙЈ¬ДҝөДКЗЦШҳӢУ^ңyРтБРЎЈЖдЕcОД«I[2,9]І»Н¬Ц®МҺФЪУЪЈ¬УЙлSҷCЧғБҝztІЙҳУЦөәННЖ”аҫWҪjЦРTransformer ҫҺҙaЖчФЪt•rҝМөДЭ”іцetЙъіЙt•rҝМөДУ^ңyЧғБҝЈ¬¶шІ»ғHТАЩҮлSҷCЧғБҝztЎЈЯ@КЗУЙУЪet°ьә¬БЛҒнЧФЭ”ИлУ^ңyРтБРx1:TөДИ«ҫЦ•rРтМШХчЈ¬ДЬүтёьәГөШЦШҳӢУ^ңyРтБРЎЈН¬•rЈ¬MLP ҫWҪjҪYҳӢәҶҶОЈ¬ҪөөНБЛST-MTS-AD ҫWҪjөДҸНлsРФЎЈST-MTS-AD ЙъіЙҫWҪjөДВ“әПёЕВК·ЦІјһй
ҲD3 ST-MTS-AD ДЈРНЙъіЙҫWҪjҪYҳӢ
ЖдЦРЈ¬ҰОЎ«N(0,I)Ј¬ЎСұнКҫПтБҝФӘЛШіЛ·eЈ¬әН·Ц„eұнКҫУЙҲD2 НЖ”аҫWҪjЙъіЙөДztҪьЛЖәутһ·ЦІјҫщЦөәНҳЛңК·ҪІоЎЈ
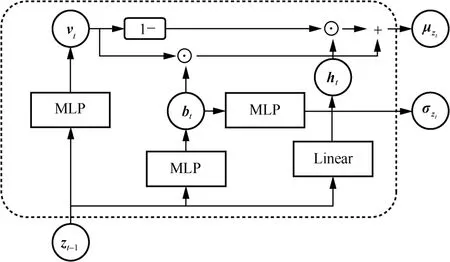
ҲD4 GTF ҫWҪjҪYҳӢ
КҪ(16)ұнКҫҫЯУРReLU әНSigmoid јӨ»оәҜ”өөДMLPЈ¬КҪ(17)ұнКҫҫЯУРReLU јӨ»оәҜ”өөДMLPЈ¬КҪ(18)ұнКҫLinear ҢУЈ¬КҪ(20)ұнКҫҫЯУРReLU әНSoftplus јӨ»оәҜ”өөДMLPЎЈ
2.4 ғһ»ҜДҝҳЛ
ST-MTS-AD ДЈРНөДғһ»ҜДҝҳЛһйЧоҙу»ҜКҪ(21)ЛщКҫөДЧC“юПВҪзЈЁELBO,evidence lower boundЈ©ЎЈ
Лг·Ё1ST-MTS-AD ДЈРНөДУ–ҫҡЛг·Ё


3 ҢҚтһ
3.1 ҢҚтһ”ө“юјҜј°ӯhҫі
ҢҚтһІЙУГТФПВ4 ӮҖ№«й_өД”ө“юјҜЈәSMDЈЁserver machine datasetЈ©ҒнЧФТ»јТҙуРН»ҘВ“ҫW№«ЛҫһйЖЪ5 ЦЬөД·ю„ХЖчҷzңy”ө“юјҜ[2]Ј»MSLЈЁmars science laboratoryЈ©әНSMAPЈЁsoil moisture active passive satelliteЈ©ҒнЧФNASA әҪМмЖчұOңyПөҪyҲуёжЦРөДЯbёР”ө“ю[12]Ј»SWaTЈЁsecure water treatmentЈ©ҒнЧФТ»ӮҖЛ®МҺАнҸSРЕПўОпАнПөҪyһйЖЪ11 МмөДұOҝШ”ө“юјҜ[3]ЎЈёч”ө“юјҜҫЯуwөДГиКцИзұн1 ЛщКҫЎЈ
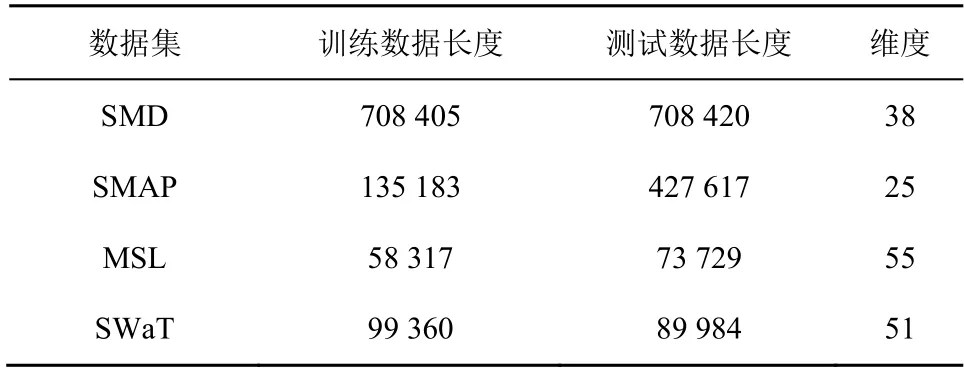
ұн1 ёч”ө“юјҜҫЯуwөДГиКц
ҢҚтһУІјюӯhҫіИзПВЈәUbuntu16.04 ІЩЧчПөҪyЈ¬Inter Xeon Gold 5220R CPUЈ¬NVIDIA Tesla T4 п@ҝЁЎЈЬӣјюӯhҫіИзПВЈәPython3.6Ј¬Pytorch 1.10.1ЎЈ
3.2 ҢҚтһДЈРН…ў”өФOЦГәНФuғrЦёҳЛ
ST-MTS-AD ДЈРНФЪSMDЎўSMAPЎўMSLЎўSWaT”ө“юјҜЙПөД»¬„Уҙ°ҝЪҙуРЎwЎў»¬„УІҪ·щlЎўУ^ңyРтБРйL¶ИTәНЧФЧўТвБҰо^”өH·Ц„eФOһй10Ўў10Ўў200әН8ЎЈёщ“ю”ө“юјҜөДҫS¶ИҙуРЎЈ¬ДЈРНФЪSMD әНSWaT”ө“юјҜЙПөДTransformer ҫҺҙaЖчЭ”іцҫS¶Иd·Ц„eФOһй128 әН256Ј¬ФЪSMAP әНMSL ”ө“юјҜЦРФOһй64ЎЈҢҚтһК№УГAdam ғһ»ҜЖчЈ¬ФOЦГҢWБ•ВКr=0.000 1Ј¬ЕъМҺАнҙуРЎbatch=64Ј¬У–ҫҡЦЬЖЪ”өepoch=200ЎЈ
ST-MTS-AD ДҝҳЛКЗҷzңyУ^ңyРтБРx1:TЦРУ^ңyЧғБҝxtКЗ·с®җіЈЎЈФЪңyФҮјҜЦРЈ¬ИфУ^ңyЧғБҝxtұнКҫөД»¬„Уҙ°ҝЪЦРДіТ»•rйgьcИЎЦөkҰУЎКRMһй®җіЈьcЈ¬„txtҳЛУӣһй®җіЈЎЈҢҰУЪңyФҮјҜЦРөДГҝӮҖУ^ңyЧғБҝxtЈ¬Из№ыЦШҳӢіцөДУ^ңyЧғБҝұ»ЕР”аһй®җіЈЈ¬ЗТxtХжҢҚҳЛәһТІһй®җіЈЈ¬„tУӣһйХжк–ЈЁTPЈ©ЎЈИз№ыЦШҳӢіцөДУ^ңyЧғБҝұ»ЕР”аһй®җіЈЈ¬ө«xtХжҢҚҳЛәһһйХэіЈЈ¬„tУӣһйјЩк–ЈЁFPЈ©ЎЈИз№ыЦШҳӢіцөДУ^ңyЧғБҝұ»ЕР”аһйХэіЈЈ¬ө«xtХжҢҚҳЛәһһй®җіЈЈ¬„tУӣһйјЩкҺЈЁFNЈ©ЎЈИз№ыЦШҳӢіцөДУ^ңyЧғБҝұ»ЕР”аһйХэіЈЈ¬ЗТxtХжҢҚҳЛәһһйХэіЈЈ¬„tУӣһйХжкҺЈЁTNЈ©ЎЈұҫОДК№УГ3 ӮҖЦёҳЛҒнәвБҝ®җіЈҷzңyДЈРНөДРФДЬЈ¬·Ц„eһйҫ«ҙ_ВКPrecisionЎўХЩ»ШВКRecallЎўF1 ·Ц”өЈ¬ЖдЦРЈ¬F1 ·Ц”өһйҫ«ҙ_ВКәНХЩ»ШВКөДХ{әНЖҪҫщ”өЈ¬F1·Ц”өФҪҙуұнКҫ®җіЈҷzңyДЈРНөДРФДЬФҪәГЎЈ
3.3 ҢҚтһҪY№ыЕc·ЦОц
ЯxИЎ6 ·NЕcST-MTS-AD ПакPөД®җіЈҷzңyДЈРНЯMРРҢҚтһҢҰұИЈ¬·Ц„eһйDAGMM[6]ЎўLSTM-VAE[8]ЎўMSCRED[15]ЎўUSADЈЁunsupervised anomaly detectionЈ©[16]ЎўOmniAnomaly[2]ЎўSDFVAE[9]ЎЈёчДЈРНөДҢҚтһҫщІЙУГұҫОДөД”ө“юоAМҺАн·ҪКҪЈ¬І»Н¬ДЈРНөДРФДЬҢҰұИИзұн2 ЛщКҫЎЈ
ҸДұн2 ҝЙЦӘЈ¬ST-MTS-AD ДЈРНФЪSMDЎўSMAPЎўMSL әНSWaT ”ө“юјҜЙПөДF1 ·Ц”ө·Ц„eһй0.933 2Ўў0.966 4Ўў0.981 9 әН0.834 2Ј¬ПаЭ^УЪ5 ·NҢҰұИДЈРНХыуwЙПУРЭ^ёЯөДМбЙэЎЈФЪSMDЎўSMAPЎўMSL әНSWaT”ө“юјҜЙПЈ¬ST-MTS-AD ДЈРНөДF1 ·Ц”өұИMSCRED·Ц„eМбёЯБЛ15.6%Ўў10.0%Ўў4.7%әН3.3%Ј¬ST-MTS-ADДЈРНөДF1 ·Ц”өұИUSAD ДЈРН·Ц„eМбёЯБЛ9.6%Ўў6.9%Ўў15.6%әН3.0%Ј¬ЕcMSCRED ПаұИЈ¬ST-MTS-AD ФЪSMD ”ө“юјҜЙПөДF1 ·Ц”өМбёЯЧо¶аЈ¬Я@КЗТтһйSMD”ө“юјҜЦРҙжФЪіЦАm•rйg¶МЎў®җіЈЖ«ІоЭ^РЎөДИЎЦөЖ¬¶О[9]Ј¬MSCRED ДЈРНЦРөДҳӢФмәһГыҫШкҮҹo·ЁІ¶«@Я@Р©јҡОўөД®җіЈМШХчЎЈUSAD лmИ»ІЙУГҢҰҝ№ҢWБ•ІЯВФұЬГвЧФҫҺҙaЖчҹo·ЁНЁЯ^ЦШҳӢХ`Іо…^·ЦХэіЈҳУұҫЕc®җіЈҳУұҫөДҶ–о}Ј¬ө«ЖдЧФҫҺҙaЖчҫWҪjӣ]УРІ¶«@MTS өД•rРтТАЩҮМШХчЎЈҢҚтһҪY№ыТІтһЧCБЛ»щУЪЦШҳӢөДлSҷCРФДЈРНST-MTS-AD өД®җіЈҷzңyР§№ыәГУЪ»щУЪЦШҳӢөДҙ_¶ЁРФДЈРНMSCRED әНUSADЎЈ
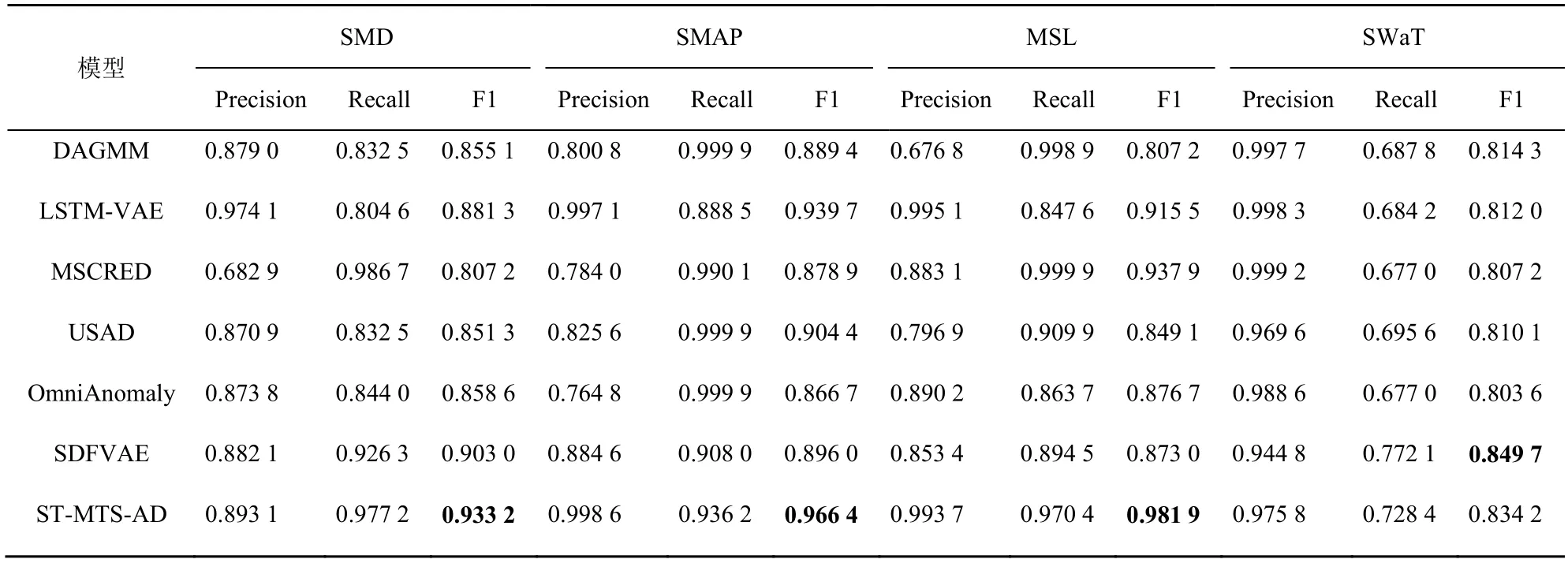
ұн2 ST-MTS-AD ДЈРНЕc6 ·NДЈРНөДРФДЬҢҰұИ
DAGMM өДF1 ·Ц”өФЪSMDЎўSMAPЎўMSLәНSWaT ”ө“юјҜЙПұИST-MTS-AD ДЈРН·Ц„eөН8.4%Ўў7.9%Ўў17.7%әН2.3%Ј¬DAGMM лmҢЩУЪ»щУЪЦШҳӢөДлSҷCРФДЈРНЈ¬ө«ЖдЧФҫҺҙaЖчҫWҪjҪYҳӢФOУӢГжПтұнёс”ө“юЈ¬ҹo·ЁМбИЎ MTS •rРтМШХчЎЈST-MTS-AD ДЈРНФЪSMDЎўSMAP әНMSL ”ө“юјҜЙПөДF1 ·Ц”өұИSDFVAE ·Ц„eМбёЯБЛ3.3%Ўў7.8%әН12.4%Ј¬ө«ФЪSWaT ”ө“юјҜЙПөДF1 ·Ц”өұИSDFVAE өН 1.8%Ј¬Я@КЗУЙУЪSDFVAE ұИST-MTS-AD ДЈРНУРЭ^ҸҠөДҝ№ФлДЬБҰЎЈLSTM-VAEәНOmniAnomalyһйЕcST-MTS-ADЧоПакPөДДЈРНЈ¬ҫщһй»щУЪVAE өДРтБРЙъіЙДЈРНЎЈФЪSMDЎўSMAPЎўMSL әНSWaT ”ө“юјҜЙПЈ¬ST-MTS-AD ДЈРНөДF1·Ц”өұИLSTM-VAE ДЈРНМбёЯБЛ5.9%Ўў2.8%Ўў7.3%әН2.7%Ј¬ұИOmniAnomaly ДЈРНМбёЯБЛ8.6%Ўў11.5%Ўў11.9%әН3.8%ЎЈЯ@КЗУЙУЪLSTM-VAE ДЈРНҹo·ЁҪЁДЈл[ҝХйgЦРлSҷCЧғБҝЦ®йgөД•rРтТАЩҮРФЎЈOmniAnomaly ДЈРН»щУЪRNN ёч•rҝМөДл[ПтБҝҢҚ¬FлSҷCЧғБҝйg•rРтТАЩҮРФЈ¬Я@·NҷCЦЖҹo·ЁҢҚ¬FлSҷCЧғБҝйgөДйL•rТАЩҮкPВ“Ј¬ЖдІЙУГөД»щУЪLGSSM өДлSҷCЧғБҝПИтһ·ЦІјЙъіЙ·ҪКҪҹo·ЁҢҚ¬FлSҷCЧғБҝйgөД·ЗҫҖРФЮD“QЈ¬ЗТФ“ДЈРНФЪЙъіЙҫWҪjЦРғHТАЩҮёч•rҝМлSҷCЧғБҝөДІЙҳУЦөЈ¬ӣ]УРАыУГНЖ”аҫWҪjRNN өДл[ПтБҝРЕПўЎЈ
3.4 ПыИЪҢҚтһ
һйБЛтһЧCST-MTS-AD ДЈРНПакPДЈүKФOУӢөДУРР§РФЈ¬ҢўST-MTS-AD ДЈРНЕcЖд3 ӮҖЧғуwЯMРРҢҰұИЈ¬3 ӮҖЧғуw·Ц„eһйST-MTS-AD-1ЎўST-MTS-AD-2 әНST-MTS-AD-3ЎЈST-MTS-AD-1 ДЈРНұнКҫФЪҲD1 өДST-MTS-AD ДЈРН»щөAЙПҢўНЖ”аҫWҪjЦРTransformerҫҺҙaЖчМж“QһййTҝШСӯӯhҶОФӘЈЁGRU,gate recurrent unitЈ©ЙсҪӣҫWҪjЎЈST-MTS-AD-2 ДЈРНұнКҫҢўST-MTS-AD ДЈРНЦРУГУЪЙъіЙлSҷCЧғБҝПИтһ·ЦІјөДGTF Мж“QһйLGSSMЎЈST-MTS-AD-3 ДЈРНұнКҫҲD1ЙъіЙҫWҪjИҘіэБЛetЧчһйЭ”ИлөДФOУӢЈ¬ЙъіЙҫWҪjөДЭ”ИлғHҒнЧФлSҷCЧғБҝztөДІЙҳУЦөЎЈёчДЈРНФЪ4 ӮҖ”ө“юјҜЙПөДҢҚтһҪY№ыИзҲD5 ЛщКҫЎЈ
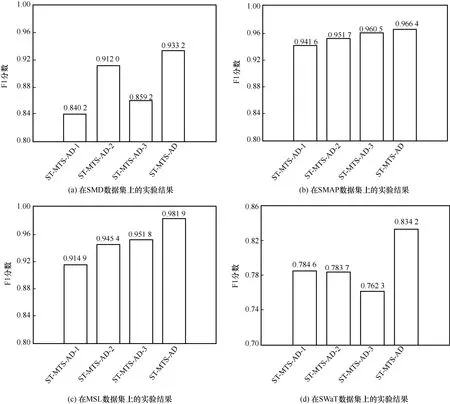
ҲD5 І»Н¬”ө“юјҜЙПөДПыИЪҢҚтһ
ҸДҲD5 ҝЙЦӘЈ¬ST-MTS-AD ДЈРНФЪSMDЎўSMAPЎўMSL әНSWaT ”ө“юјҜЙПөДF1 ·Ц”өұИST-MTS-AD-1ДЈРН·Ц„eМбёЯБЛ11.1%Ўў2.6%Ўў7.3%әН6.3%Ј¬ТтҙЛ»щУЪTransformer ҫҺҙaЖчЙъіЙөД•rРтТАЩҮМШХчДЬёьәГөШҢҚ¬Fл[ҝХйgЦРлSҷCЧғБҝйgөД•rРтТАЩҮРФЎЈST-MTS-AD ДЈРНөДF1 ·Ц”өұИST-MTS-AD-2 ДЈРН·Ц„eМбёЯБЛ2.3%Ўў1.5%Ўў3.9%әН6.4%Ј¬ФӯТтКЗGTFІЙУГGRU өДЛјПлҢҰлSҷCЧғБҝzt-1өҪztөДЮD“QәҜ”өЯMРР…ў”ө»ҜЈ¬НЁЯ^·ЗҫҖРФЮD“QәҜ”өҝШЦЖzt-1өҪztөДРЕПўӮчЯfЈ¬ҝЙТФІ¶«@лSҷCЧғБҝЦ®йgёьҸНлsөДТАЩҮРФЈ¬¶шLGSSM АыУГҝЁ –ВьһVІЁөДЛјПлҢҚ¬FлSҷCЧғБҝйgөДҫҖРФЮD“QЈ¬ҪY№ыЧCГчБЛST-MTS-AD К№УГGTFөДЯBҪУ·ҪКҪұИК№УГLGSSM өДЯBҪУ·ҪКҪёьјУУРР§ЎЈST-MTS-AD ДЈРНөДF1 ·Ц”өФЪSMDЎўSMAPЎўMSLәНSWaT ”ө“юјҜ·Ц„eұИST-MTS-AD-3 ДЈРНМбёЯБЛ8.6%Ўў0.6%Ўў3.2%әН9.4%Ј¬УЙTransformer ҫҺҙaЖчЙъіЙйL•rТАЩҮМШХчetәННЖ”аҫWҪjЙъіЙөДлSҷCЧғБҝztөДІЙҳУЦөДЬёьәГөШЦШҳӢMTS ёч•rҝМxЎдtөД·ЦІјЎЈБнНвЈ¬ЕcST-MTS-AD-1ЎўST-MTS-AD-2 әНST-MTS-AD-3ПаұИЈ¬ST-MTS-AD ФЪSMAP ”ө“юјҜЙПөДөДF1 ·Ц”өМбёЯІўІ»Гчп@ЎЈЯ@КЗТтһйSMAP ”ө“юјҜЦРҙжФЪәЬ¶алxЙўЧғБҝЈ¬Жд®җіЈЖ¬¶ОұИЭ^ИЭТЧұ»ҷzңyЎЈ
4 ҪYКшХZ
ұҫОДМбіцБЛТ»·NИЪәПTransformer ҫҺҙaЖчәНVAE өДлSҷCTransformer MTS ®җіЈҷzңyДЈРНЎЈФ“ДЈРН»щУЪTransformer ҫҺҙaЖчЙъіЙөД•rРтМШХчҢҚ¬Fл[ҝХйgЦРлSҷCЧғБҝйgөДйL•rТАЩҮРФЈ¬ІЙУГйTҝШЮD“QәҜ”өЙъіЙ•rРтлSҷCЧғБҝөДПИтһ·ЦІјЈ¬УЙНЖ”аҫWҪjЙъіЙөДёч•rҝМлSҷCЧғБҝҪьЛЖәутһ·ЦІјІЙҳУЦөәНTransformer ҫҺҙaЖчЭ”іцөД•rРтМШХчЦШҳӢMTS ёч•rҝМИЎЦөөД·ЦІјЎЈФЪ4 ӮҖ№«й_”ө“юјҜЙПҢҚтһҪY№ыұнГчБЛST-MTS-AD ФOУӢөДУРР§РФЎЈПВТ»ІҪ№PХЯҢўСРҫҝИзәО»щУЪTransformer ҫҺҙaЖчҢҚ¬Fл[ҝХйgЦРлSҷCЧғБҝйgөД·ЗсR –ҝЙ·т„У‘BРФЎЈ